
どうもリンです。
前回、OptunaでLightGBMのハイパーパラメータを自動でチューニングしてみました。
↓前回の記事

で、今回はこのOptunaでもっと便利な機能を見つけたので紹介しようと思います。
結論から言うと、LightGBM専用のチューニング機能を使うとチューニング時間がめちゃめちゃ短縮し、割と高い精度を出してくれるって感じです。
きっとこの機能は流行るだろうなぁ…
ではいきましょう!
Optunaの新機能「Stepwise Tuning」
さて、今回紹介する新機能は「Stepwise Tuning」と言います。つまり段階的にチューニングしようって意味ですね。
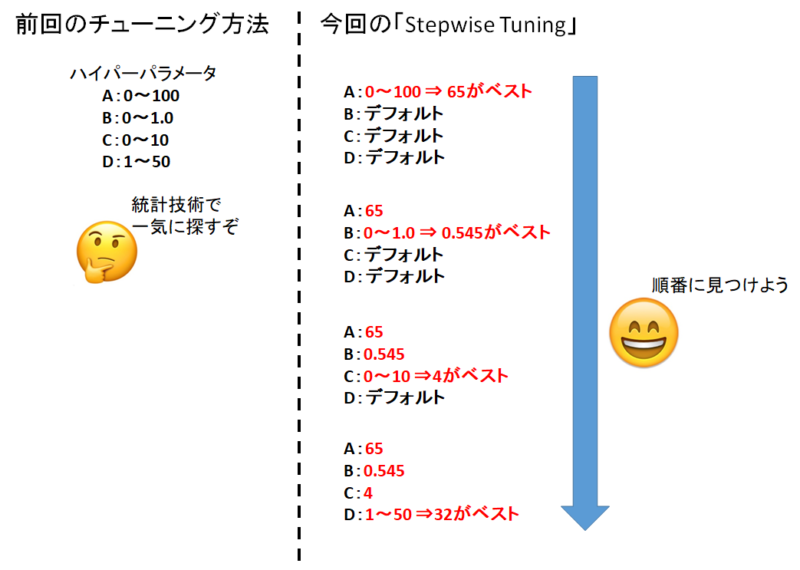
前回の記事で行ったチューニング方法は何個もあるハイパーパラメータを統計技術を使って効率的に探索するというものでした。
「Stepwise Tuning」のイメージは、一つ一つのハイパーパラメータを順番に振っていって一番良い値を一つずつ見つけましょうって感じです。
なんだか「Stepwise Tuning」って簡単そうですよね。
そうなんです。簡単だから昔から行われている手法なんです。
しかし簡単だからといって侮ることなかれ。
実は精度の良いパラメータを見つける順番やコツなんかは既にたくさん議論されてます。
今回のLightGBM用「Stepwise Tuning」は、このようなコツを基に自動でチューニングを行う機能なんですね。
さっそく「Stepwise Tuning」を実装してみる
では早速Optunaを使ってハイパーパラメータチューニングをしてみましょう
ライブラリのインポート
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #データ解析用ライブラリ import pandas as pd import numpy as np #データ可視化ライブラリ import matplotlib.pyplot as plt import seaborn as sns #LightGBMライブラリ import lightgbm as lgb #訓練データとモデル評価用データに分けるライブラリ from sklearn.model_selection import train_test_split #ハイパーパラメータチューニング自動化ライブラリ import optuna #LightGBM用Stepwise Tuningに必要 from optuna.integration import lightgbm_tuner #関数の処理で必要なライブラリ from sklearn.metrics import mean_squared_error from sklearn.metrics import r2_score |
今回はStepwise Tuningに必要なlightgbm_tunerを入れます。それ以外は前回の記事と一緒。
CSVファイルの取り込み
1 | concrete_data = pd.read_csv(r'C:\Users\concrete.csv', engine='python') |
例によって、コンクリートデータが入っているパスを入れてくださいね。
コンクリートデータを持っていない方は↓の記事からダウンロードしてください。
出来れば今までの記事を見ておくことをオススメします。

訓練用データとモデル評価用データに分割
1 | train_set, test_set = train_test_split(concrete_data, test_size=0.2, random_state=4) |
ここで、コンクリートデータを「訓練用」と「モデル評価用」に分けます。今回も8:2でいきましょう。
1 2 | print(len(train_set)) print(len(test_set)) |
訓練用データは824セット。モデル評価用データは206セットと表示されます。8:2ですね。
説明変数と目的変数に分割
1 2 3 4 5 6 7 | #訓練データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_train = train_set.drop('Concrete compressive strength', axis=1) y_train = train_set['Concrete compressive strength'] #モデル評価用データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_test = test_set.drop('Concrete compressive strength', axis=1) y_test = test_set['Concrete compressive strength'] |
前回の記事通り。
説明変数と目的変数を「LightGBM用のデータセット」に加工します。
1 2 | lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test) |
こうすることで高速化できるんでしたよね。
パラメータの指定
1 2 | params = {'objective': 'regression', 'metric': 'rmse'} |
パラメータの一部を指定します。とは言っても、「やることは回帰だよ、評価はRMSEでやってね」だけですけどね。
LightGBMモデル構築→Stepwise Tuning
1 2 3 4 5 6 7 8 9 10 11 | best_params = {} tuning_history = [] gbm = lightgbm_tuner.train(params, lgb_train, valid_sets=lgb_eval, num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50, best_params=best_params, tuning_history=tuning_history) |
さて、前回のLightGBMモデル構築の時と、少しだけ引数が増えてますね。
best_paramsにはStepwise Tuningで調整されたベストのパラメータが格納されます。
tuning_historyにはどんなチューニングを試したか、その履歴が格納されます。
そしてgbmには「チューニングされたパラメータを用いて構築されたLightGBMモデルが格納されます。
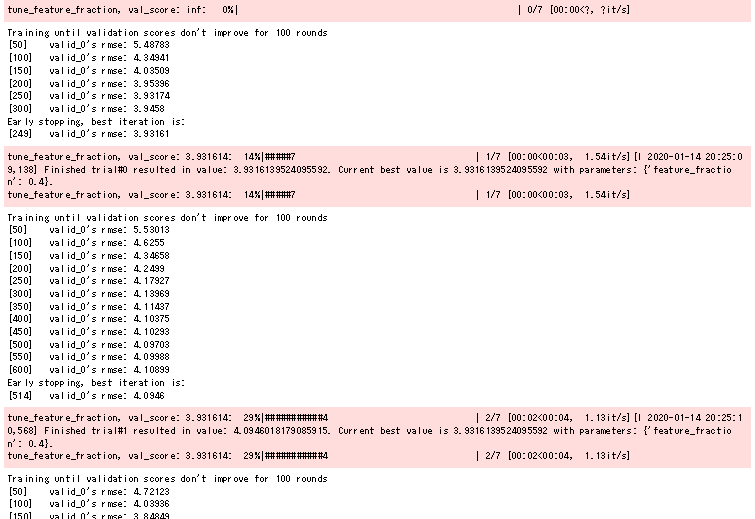
実行すると↑みたいな感じで「現状何のパラメータをチューニングしているか」「そのパラメータチューニングの進行状況」「モデル評価用データでの評価指数」などが出力されますね。
1分くらいでチューニング・モデル構築が終了します。とってもはやい。
結果の出力
では実際にモデル評価用データを使って、毎度おなじみ予測値正答値マップを作っていきましょう。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #予測値と正解値を描写する関数 def True_Pred_map(pred_df): RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) R2 = r2_score(pred_df['true'], pred_df['pred']) plt.figure(figsize=(8,8)) ax = plt.subplot(111) ax.scatter('true', 'pred', data=pred_df) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') plt.text(0.1, 0.9, 'RMSE = {}'.format(str(round(RMSE, 5))), transform=ax.transAxes, fontsize=15) plt.text(0.1, 0.8, 'R^2 = {}'.format(str(round(R2, 5))), transform=ax.transAxes, fontsize=15) |
まずは予測値正答値マップの関数から。
1 2 3 4 5 6 7 8 9 | #モデル評価用データを入れて、予測値を出力 predicted = gbm.predict(X_test) #予測値と正答値を、可視化関数にぶち込めるように加工 pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] #可視化関数の起動 True_Pred_map(pred_df) |
そしたら予測値を出して、可視化しましょう!
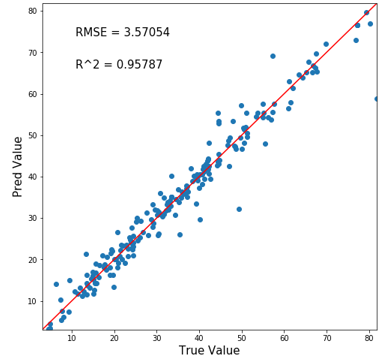
ほえ~。めちゃ精度いい。
ちなみに前回のチューニング(1時間掛かった)との比較がこちら。
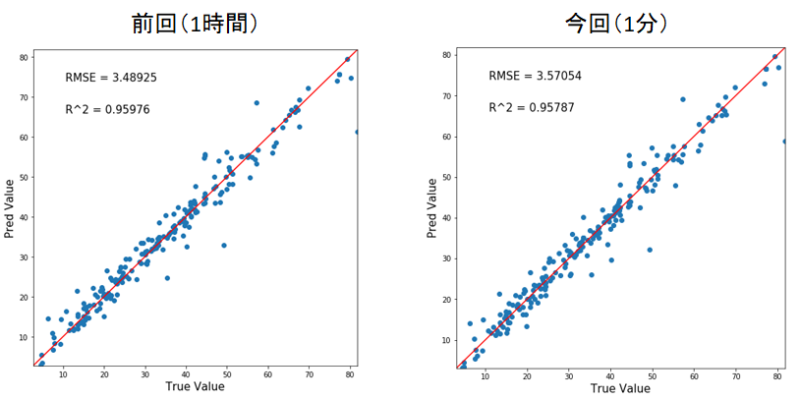
うーん。遜色なし!!素晴らしい精度と計算時間でしたね。
ベストパラメータと履歴の表示
せっかくですし、チューニングされたパラメータはどんな値なのか、そしてチューニング履歴も見てみましょう。
1 2 | print(best_params) print(tuning_history) |
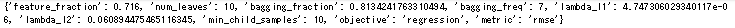
ふーむ。前回の記事でチューニングした結果が↓
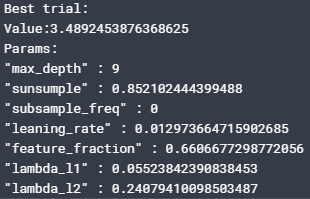
色々使わないパラメータもあるんですねぇ。
履歴は↓のように出力されます。
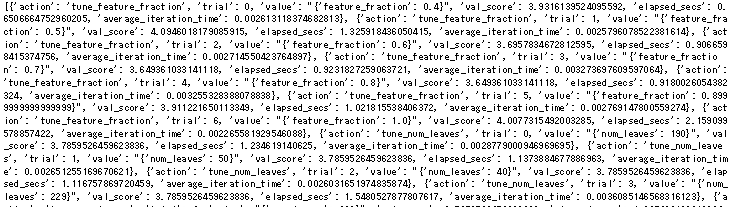
見づらい…せめてpandasDataFrameで出力してくれ。
要約すると
①feature_fraction
②num_leaves
③bagging_fraction
④bagging_fraction と bagging_freq同時
⑤feature_fraction
⑥lambda_l1_and_lambda_l2
⑦min_child_samples
って順番でチューニングしていました。
毎回このルールでチューニングするのかは謎。ソースコードってどっかに転がっているんですかね?
「Stepwise Tuning」のメリット・デメリット
さて、前回のチューニング方法と今回の「Stepwise Tuning」のメリットデメリットを私なりにまとめてみました。
ということで、自動Stepwise Tuningは「とりあえず最適化して別の部分(特徴量作成など)でのモデル改良を迅速にしたい」という時に効果的かなと感じました。
なんだか流行りそうなのでぜひ使ってみてください!
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
そして世界に革命を起こすこと間違いなしの機械学習全自動化ライブラリ「PyCaret」の使用方法や、今後の社会を予想した
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
も同時発売中です。
「PyCaret」を使いこなせば、22種類もの機械学習手法と一気に比較したり、ブラックボックスであるモデル内部の解析までわずか10数行のコードで行うことができます!
中身はこんな感じ↓
- Pythonのインストール
- Anaconda「JupyterNotebook」の起動
- 仮想環境構築
- データセット
- 中身の確認
- PyCaretを実装する
- ライブラリのインポート
- データ型を推測させる
- モデルの構築
- モデルの選択
- ハイパーパラメータチューニング
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- 機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
Python初心者でもインストール~全自動ライブラリ実装・解析まで出来るようになります。
980円:11080文字の教科書になっています。
全自動でもいいからパッと機械学習を実装したい!
「PyCaret」のような最新技術を使いこなしたいな。
という方には非常にオススメです。是非一読あれ!
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座

コメント