どうもリンです。AIベンチャー出向中で修行しています。主言語はPythonです。
最近は決定木系機械学習が活躍する時期なので知見を積み上げております。
決定木系機械学習の真髄を知りたい!
と嘆く毎日でございます。
以前↓のような記事を執筆しました。

内容は決定木系アルゴリズムの汎化性能の可視化や、予測線を3Dで見てみるって内容です。「ほーん。各モデルの挙動ってそんな感じなんや。」という知見が得られましたので満足です。
さて、今回は同じく決定木系アルゴリズムの「学習の様子」を深堀したいと思います。
- ランダムフォレストの木の数
- LightGBMの誤差修正木の数
これらを徐々に増やしていくと、予測結果はどのように推移していくのでしょうか?
原理が分かっていればイメージができますかね。
実物が見たいので、ぜひとも実験してみましょう!
原理を知らない方は↓の記事で予習してみましょう。


データセット
今回使うデータセットは、当ブログおなじみの「コンクリートデータ」でございます。
「コンクリート材料の配合データとコンクリート強度」が載ったテーブルデータです。
使用しやすいようにCSV形式に変換しておきました。ダウンロードしてローカルに落としておいてください。
「Concrete Compressive Strength Data Set」 ←発行元
【著作権】I-Cheng Yeh, “Modeling of strength of high performance concrete using artificial neural networks,” Cement and Concrete Research, Vol. 28, No. 12, pp. 1797-1808 (1998).
中身の確認
これはカルフォルニア大学アーバイン校が公開しているオープンデータであり、1030データ入っております。
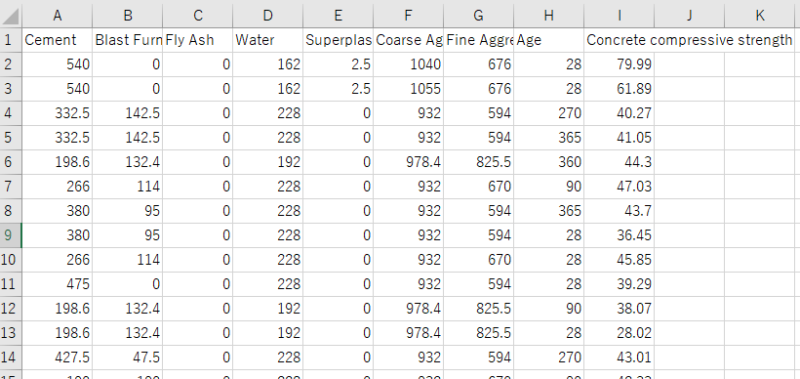
↑中身はこんな感じ。
| 説明変数 | cement : セメント(kg/㎥) Blast Furnance Slag : 高炉スラグ(kg/㎥) Fly Ash : フライアッシュ(kg/㎥) Water : 水(kg/㎥) Superplasticizer : 高流動化剤(kg/㎥) Coarse Aggregate : 粗骨材(kg/㎥) Fine Aggregate : 細骨材(kg/㎥) Age : 材齢(1〜365日) |
| 目的変数 | Concrete compressive strength : コンクリート圧縮強度(MPa) |
となっております。
材料データから、コンクリートの圧縮強度を予測しましょうってモチベーションですね。
カテゴリ変数が入っていないので簡明ですし、マテリアルズインフォマティクスに近いものを感じてなんだか楽しそうなので、当ブログのモデルデータとなっております。
ArtistAnimationでGIFを作ってみる
ほんじゃあ作っていきましょう。
説明は飛ばしがちなので、「このコードどういう意味!?」ってなったら過去記事を見返せば理解できると思います。(手抜き)
前準備
ライブラリのインポートやデータの加工をやっていきます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | #データ解析用ライブラリ import pandas as pd import numpy as np #データ可視化ライブラリ import matplotlib.pyplot as plt import seaborn as sns #ランダムフォレストライブラリ from sklearn.ensemble import RandomForestRegressor #LightGBMライブラリ import lightgbm as lgb #訓練データとモデル評価用データに分けるライブラリ from sklearn.model_selection import train_test_split #RMSEを計算させたいからRME from sklearn.metrics import mean_squared_error #コンクリートデータインポート concrete_data = pd.read_csv(r'C:\concrete.csv', engine='python') #訓練データとテストデータに分割 train_set, test_set = train_test_split(concrete_data, test_size=0.2, random_state=4) #訓練データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_train = train_set.drop('Concrete compressive strength', axis=1) y_train = train_set['Concrete compressive strength'] #モデル評価用データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_test = test_set.drop('Concrete compressive strength', axis=1) y_test = test_set['Concrete compressive strength'] #LightGBM用データセットに変換 lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test) |
ということで、訓練データとテストデータに分けるところまで一気にやっちゃいました。
LightGBMの予測挙動を出力する
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | #可視化クラス import matplotlib.pyplot as plt #アニメーションに必要なクラス import matplotlib.animation as animation #基本的なハイパーパラメータだけ設定 params = {'metric': 'rmse', 'max_depth' : 9} fig, ax = plt.subplots(figsize=(8,8)) #アニメーションの空の配列を準備。ここに動かしたいイメージを追加していく。 ims=[] #今回は1~100の繰り返しで。 for i in range(1,101): #モデルの構築する(誤差修正決定木の数をiにする) gbm = lgb.train(params, lgb_train, valid_sets=lgb_eval, num_boost_round=i, early_stopping_rounds=None, verbose_eval=50) #予測値出力 predicted = gbm.predict(X_test) #予測値と正当値を同じデータフレームにする pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] #予測値と正当値のRMSEを計算する RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) #プロットの設定を進めていく。 im = ax.scatter('true', 'pred', data=pred_df, color='blue') ax.set_title('LightGBM Learning Behavior of Testdata', fontsize=20) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) text_RMSE = ax.text(0.1, 0.9, 'RMSLE = {}'.format(str(round(RMSLE, 5))), transform=ax.transAxes, fontsize=15) text_cycle = ax.text(0.1, 0.85, 'num_boost_round = {}'.format(str(i)), transform=ax.transAxes, fontsize=15) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') #ims(空の配列)に各オブジェクトを加えていく。artistのリストのリストにする必要があるらしい。 ims.append([im]+[text_RMSE]+[text_cycle]) #GIFとして出力する。 ani = animation.ArtistAnimation(fig, ims, interval=100) ani.save("LGBM_testoutput.gif", writer="imagemagick") |
一気に行っちゃいました。
詰まりやすいのはimsの取り扱いでしょうか。

↑Qiitaのこちらの記事が参考になりました。
matplotlibではグラフオブジェクトはartistと呼び、imsはartistのリストのリストである必要があるようです。
scatterメソッドやtextメソッドはartistを返すので、imsにはそれらartistのリスト。つまりims.append([im]+[text_RMSE]+[text_cycle])のような形でartistをひとまとまりにしてimsに追加する必要があります。
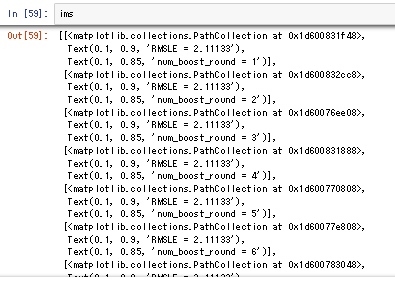
imsの中身はartistのリストが連なり、リストのリストになっていることが分かります。
さて出力を見てみましょう。私の場合はanacondaのフォルダにGIFが格納されています。
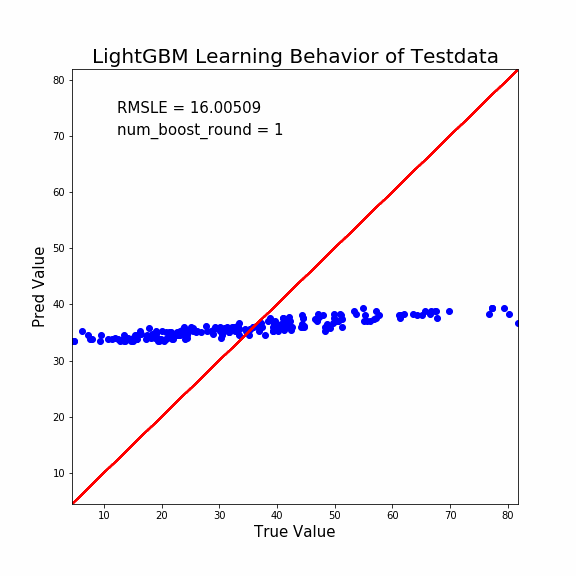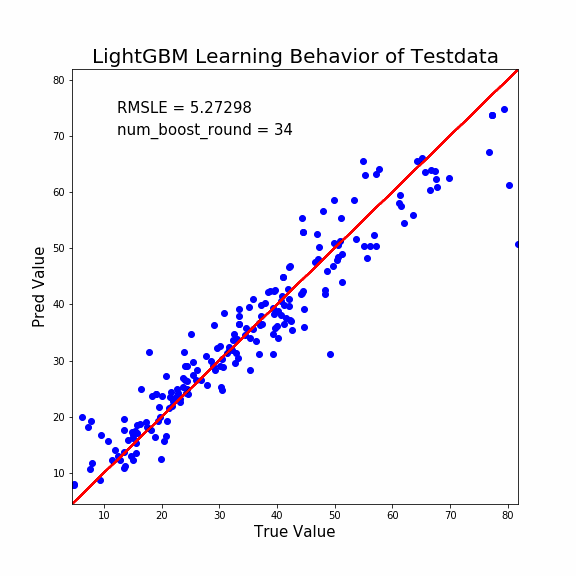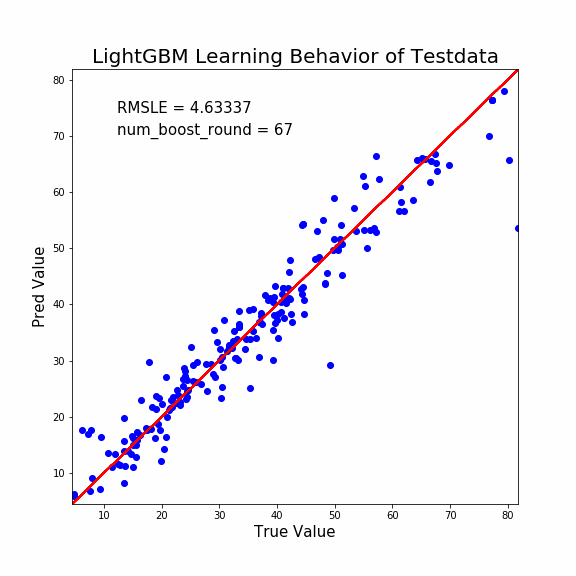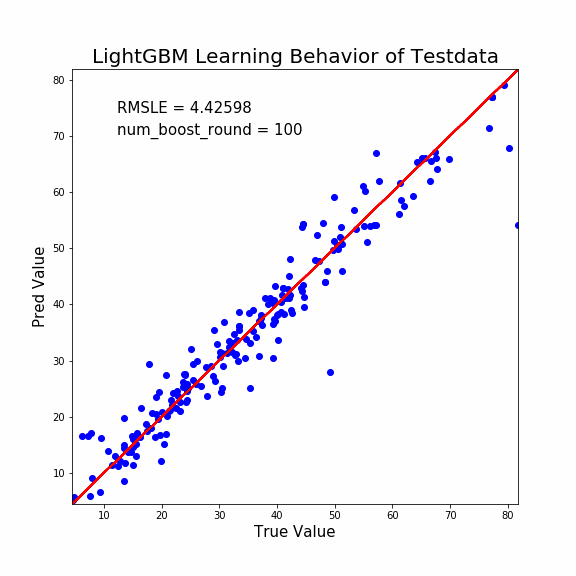
縦軸が予測値、横軸が正当値です。よって赤線に沿うほど予測能力はGOOD。
この出力はLightGBMで「モデル評価用データ」を予測させました。GIFのタイトル通りです。
追記:RMSLEじゃなくてRMSEですね。投稿してから気づきました。ゆるして。
どうでしょうか?誤差修正決定木の本数が少ないうちは予測値は一律で35MPaでしたが、誤差修正が進むと正当値に近い値に収束しています。
特に「最初の予測値が一律で35MPa付近になる」という結果が面白いですね。
ブースティング系の学習進行初期は、かなりの弱学習器を使用しているようです。
単純な決定木1本でも、こんな弱学習器ではありません。とんでもなく強い制約を掛けているようですね。もっと論文を読み込まねば(反省)
説明能力も観察する。
先ほどは「モデル評価データ」、つまり未知のデータに対する予測能力を見ていました。
では「モデル訓練データ」を予測させる、つまり既知のデータに対する説明能力がどのように変化するか見てみましょう。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | #基本的なハイパーパラメータだけ設定 params = {'metric': 'rmse', 'max_depth' : 9} fig, ax = plt.subplots(figsize=(8,8)) #アニメーションの空の配列を準備。ここに動かしたいイメージを追加していく。 ims=[] #今回は1~100の繰り返しで。 for i in range(1,101): #モデルの構築する(誤差修正決定木の数をiにする) gbm = lgb.train(params, lgb_train, valid_sets=lgb_eval, num_boost_round=i, early_stopping_rounds=None, verbose_eval=50) #予測値出力 predicted = gbm.predict(X_tain) #予測値と正当値を同じデータフレームにする pred_df = pd.concat([y_train.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] #予測値と正当値のRMSEを計算する RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) #プロットの設定を進めていく。 im = ax.scatter('true', 'pred', data=pred_df, color='blue') ax.set_title('LightGBM Learning Behavior of Traindata', fontsize=20) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) text_RMSE = ax.text(0.1, 0.9, 'RMSLE = {}'.format(str(round(RMSLE, 5))), transform=ax.transAxes, fontsize=15) text_cycle = ax.text(0.1, 0.85, 'num_boost_round = {}'.format(str(i)), transform=ax.transAxes, fontsize=15) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') #ims(空の配列)に各オブジェクトを加えていく。artistのリストのリストにする必要があるらしい。 ims.append([im]+[text_RMSE]+[text_cycle]) #GIFとして出力する。 ani = animation.ArtistAnimation(fig, ims, interval=100) ani.save("LGBM_trainoutput.gif", writer="imagemagick") |
変更点は、
- 予測値出力をX_test→X_trainにした
- pred_dfの中身をy_trainとpredicted(予測値)のDFにした。
以上です。出力を見てみましょう。
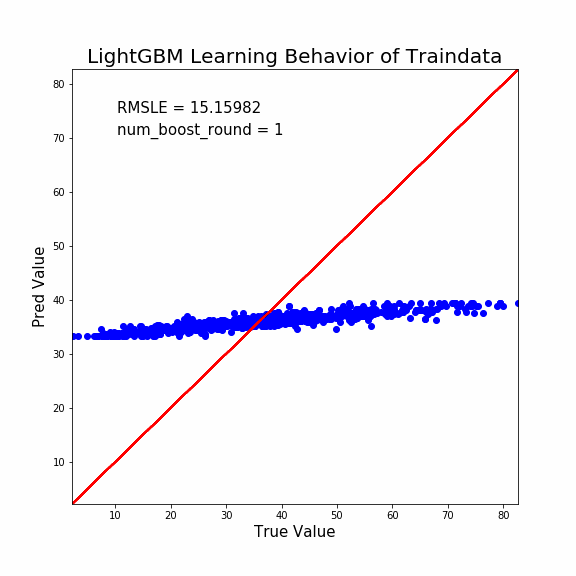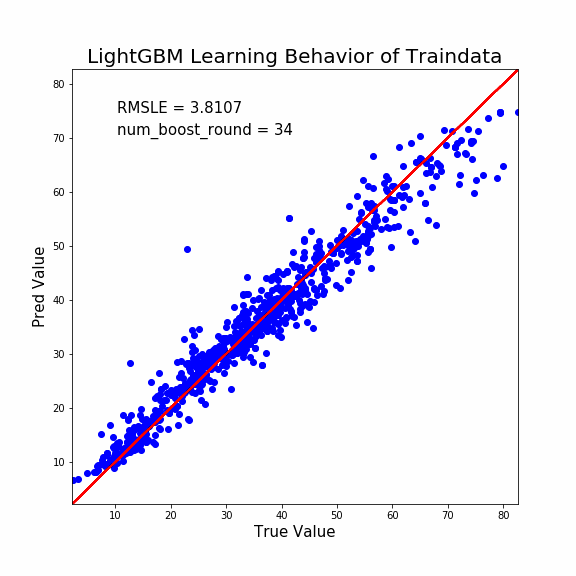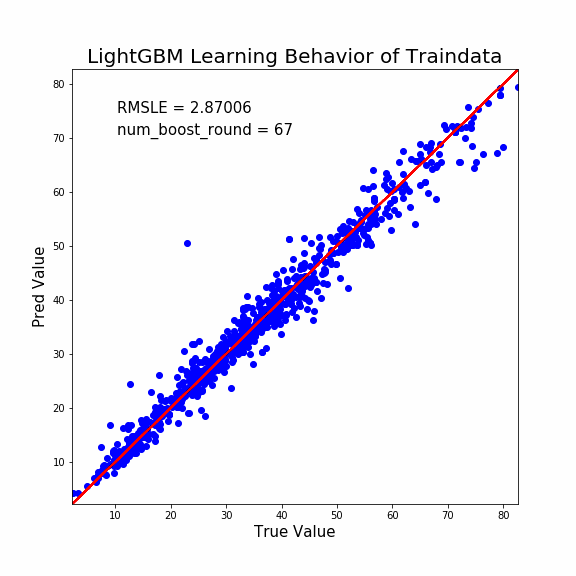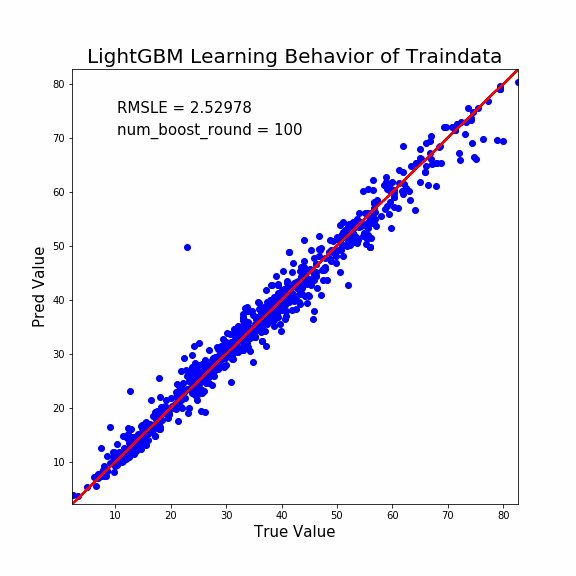
説明能力は予測能力よりも高くなります。至極当然ですね。
少し着目して貰いたい点は次の通り。
- 学習初期は誤差修正量が多い
- 学習終盤は誤差修正量が少ない
LightGBMの強みをここで感じます。
つまり「現状で誤差が大きいデータほど誤差修正量を多くしますよ」ってことです。
このような考慮をすることで、より早く学習の収束に向かうことができますよね。頭いいすねマジで。
そしてこのように説明能力のプロットをすることで「外れ値」検出もできます。
ほら。1つだけ外れてるプロットあるでしょ?これなんかおかしいですよね。
大元の材料データを用意したのは人間です。よってヒューマンエラーが往々にして生じます。
説明変数の入力にミスがあるのか、予測値の入力にミスがあるのか、測定方法のミスなのか。いずれにせよデータの再確認が必要ですね。
そして学習初期にも「大きく予測を外しているプロット」がいくつか確認できますね。これも怪しいです。
何故ならヒューマンエラーでデータがおかしいけど、モデルが試行錯誤して誤った予測方法を構築している可能性があるからです。
そのような状態は一種の過学習になります。汎化性能を落としかねません。学習初期に大きく予測を外すプロットもデータの再検証が必要でしょう。
ランダムフォレストの予測挙動を出力する
ではアンサンブル学習器の一つ「ランダムフォレスト」に行きましょう。
ブースティング系であるLightGBMとはどう変わるのでしょうか!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | fig, ax = plt.subplots(figsize=(8,8)) #アニメーションの空の配列を準備。ここに動かしたいイメージを追加していく。 ims=[] #今回は1~100の繰り返しで。 for i in range(1,101): #モデルの構築する(回帰木の数をiにする) clf = RandomForestRegressor(n_estimators=i、random_state=1) model = clf.fit(X_train, y_train) #予測値出力 predicted = model.predict(X_test) #予測値と正当値を同じデータフレームにする pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] #予測値と正当値のRMSEを計算する RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) #プロットの設定を進めていく。 im = ax.scatter('true', 'pred', data=pred_df, color='blue') ax.set_title('RandomForest Learning Behavior of Testdata', fontsize=20) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) text_RMSE = ax.text(0.1, 0.9, 'RMSLE = {}'.format(str(round(RMSLE, 5))), transform=ax.transAxes, fontsize=15) text_cycle = ax.text(0.1, 0.85, 'n_estimators = {}'.format(str(i)), transform=ax.transAxes, fontsize=15) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') #ims(空の配列)に各オブジェクトを加えていく。artistのリストのリストにする必要があるらしい。 ims.append([im]+[text_RMSE]+[text_cycle]) #GIFとして出力する。 ani = animation.ArtistAnimation(fig, ims, interval=100) ani.save("RandomForest_testoutput.gif", writer="imagemagick") |
はい。ほとんどコードは同じです。
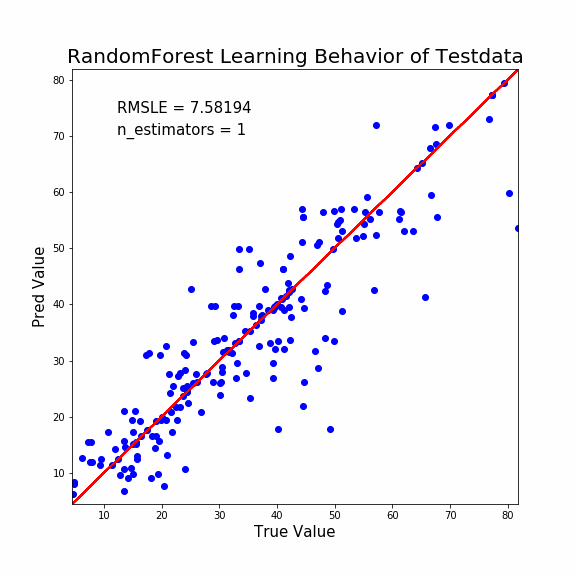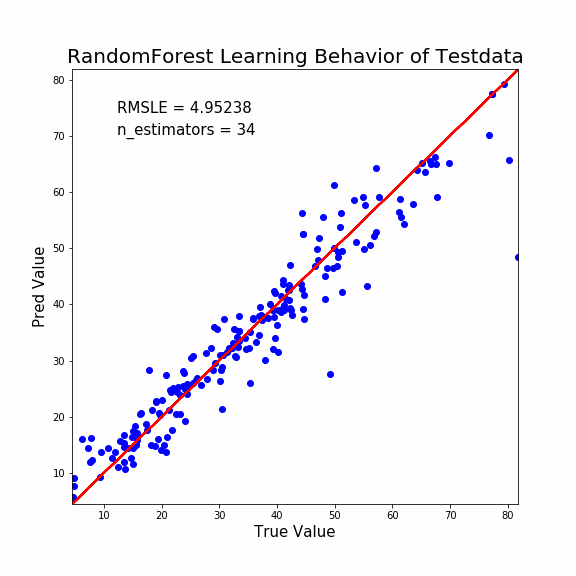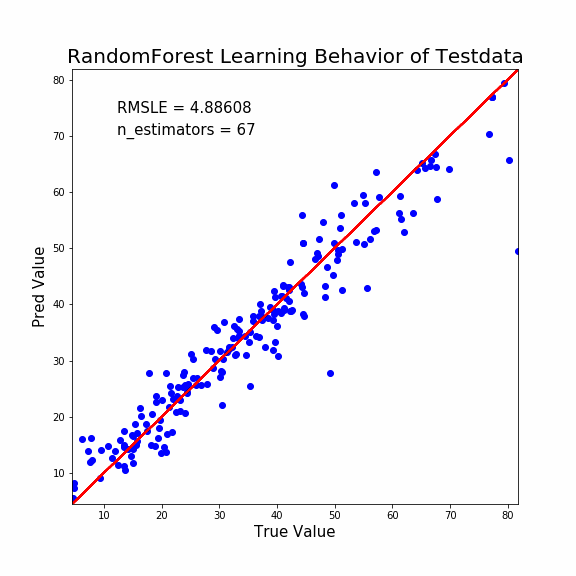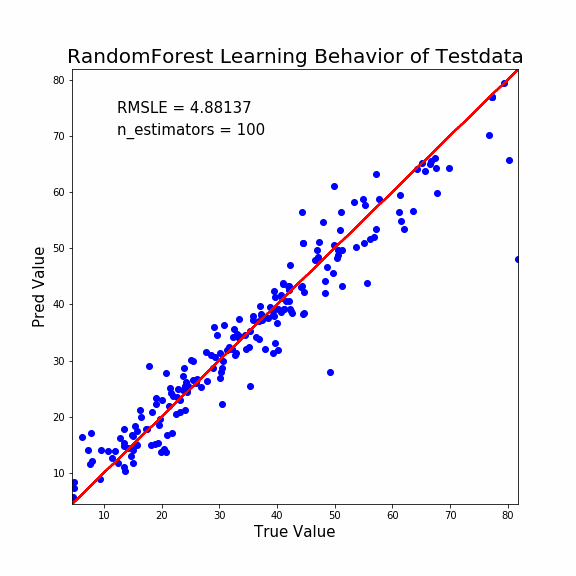
ぬ!LightGBMのときとは挙動が大きく違いますね。
- 決定木の本数が少なくても、ある程度の予測性能がある。
- 急速に収束へ向かう
このような差異があります。
ランダムフォレストは性格の異なる決定木の集合体です。
1本でもある程度の予測能力は担保されているようです。
しかし最終的な予測性能は少し悪いですね。
↑こちらの記事の最後に「何故ランダムフォレストの予測性能はブースティング系に勝てないのか」について考察を述べています。是非ご覧ください。
では最後にランダムフォレストの説明能力ですね。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | fig, ax = plt.subplots(figsize=(8,8)) #アニメーションの空の配列を準備。ここに動かしたいイメージを追加していく。 ims=[] #今回は1~100の繰り返しで。 for i in range(1,101): #モデルの構築する(回帰木の数をiにする) clf = RandomForestRegressor(n_estimators=i、random_state=1) model = clf.fit(X_train, y_train) #予測値出力 predicted = model.predict(X_train) #予測値と正当値を同じデータフレームにする pred_df = pd.concat([y_train.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] #予測値と正当値のRMSEを計算する RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) #プロットの設定を進めていく。 im = ax.scatter('true', 'pred', data=pred_df, color='blue') ax.set_title('RandomForest Learning Behavior of Traindata', fontsize=20) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) text_RMSE = ax.text(0.1, 0.9, 'RMSLE = {}'.format(str(round(RMSLE, 5))), transform=ax.transAxes, fontsize=15) text_cycle = ax.text(0.1, 0.85, 'n_estimators = {}'.format(str(i)), transform=ax.transAxes, fontsize=15) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') #ims(空の配列)に各オブジェクトを加えていく。artistのリストのリストにする必要があるらしい。 ims.append([im]+[text_RMSE]+[text_cycle]) #GIFとして出力する。 ani = animation.ArtistAnimation(fig, ims, interval=100) ani.save("RandomForest_trainoutput.gif", writer="imagemagick") |
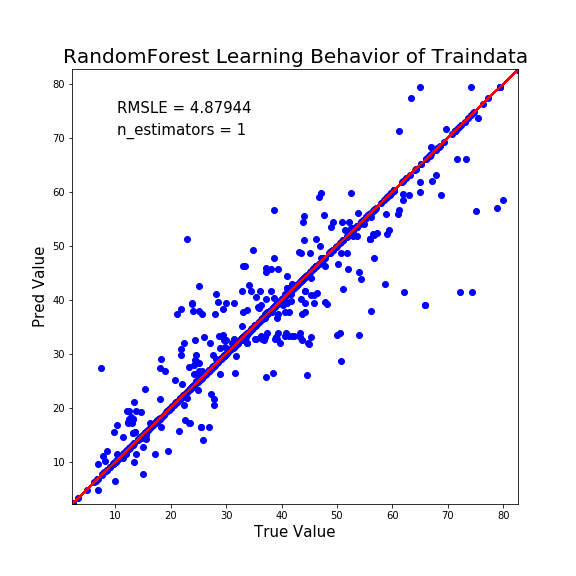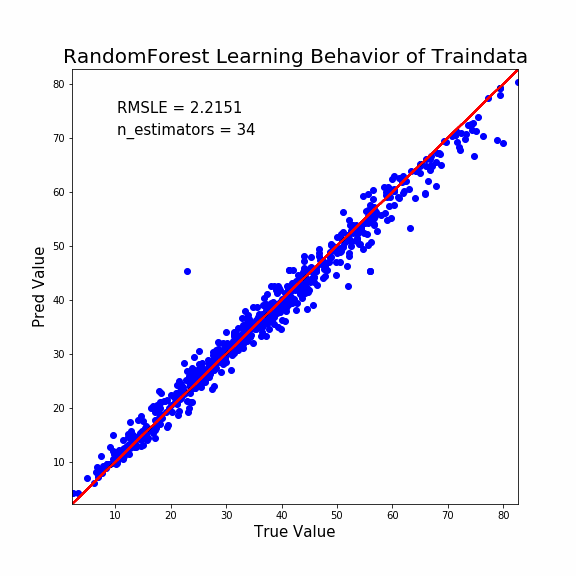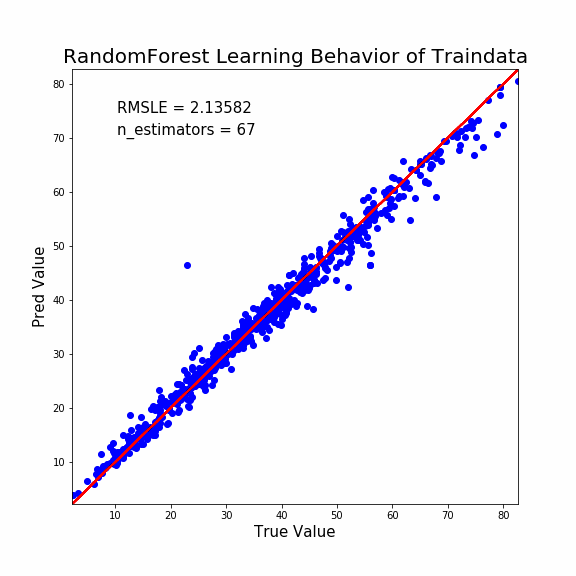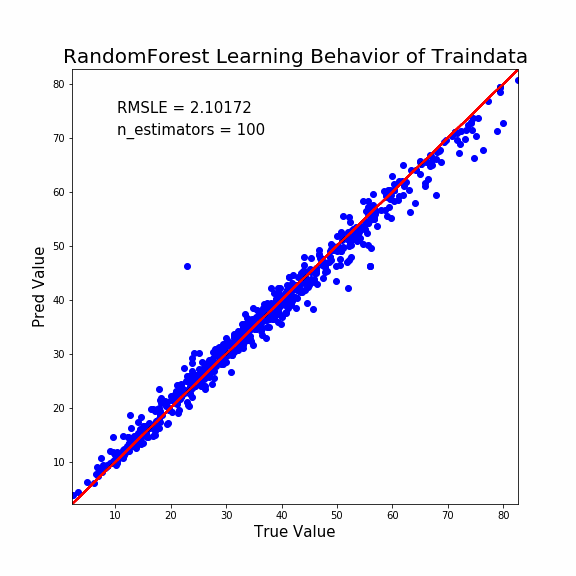
きちんと説明能力は収束していて、十分な性能ということがわかります。
そのうえで予測能力が比較的低いということは、やはりLightGBMよりも過学習しているようですね。
外れ値検出には不向きかもしれません。収束が早すぎて外れ値っぽいプロットは1点しか検出できません。
まとめ
ということで決定木系アルゴリズムの学習進行挙動を観察してみました。
アンサンブル系とブースティング系は、やはり全く挙動が違いますね。
イメージとしては理解していたけれど、実験してみると新たな発見もあって面白かったです(小並感)
こんな感じで機械学習の挙動についてちょくちょく研究しているので、是非他記事もご覧ください!
違うアプローチでの挙動観察は私の教材からどうぞ!(宣伝)↓
機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座

↓ Python学習オンラインスクールをまとめてみました ↓
↓他記事はこちら↓





コメント