
どうも、AIエンジニアリンです。
今まで機械学習やらプログラミングについて偉そうに語っておきながら実践の記事は無いんかいと思っていましたので、今回からちょっとシリーズ的な感じで実践編を書いていきます。
今回は前準備です。
実践に使うデータセットの配布と、中身の確認をしていきましょう。
今回配布するデータセットを使用して、しばらく様々な機械学習の手法を紹介していきます。
題材
今回使用するデータは「コンクリート材料の配合データとコンクリート強度」が載ったテーブルデータです。
使用しやすいようにCSV形式に変換しておきました。ダウンロードしてローカルに落としておいてください。
「Concrete Compressive Strength Data Set」 ←発行元
【著作権】I-Cheng Yeh, “Modeling of strength of high performance concrete using artificial neural networks,” Cement and Concrete Research, Vol. 28, No. 12, pp. 1797-1808 (1998).
中身の確認
これはカルフォルニア大学アーバイン校が公開しているオープンデータであり、1030データ入っております。
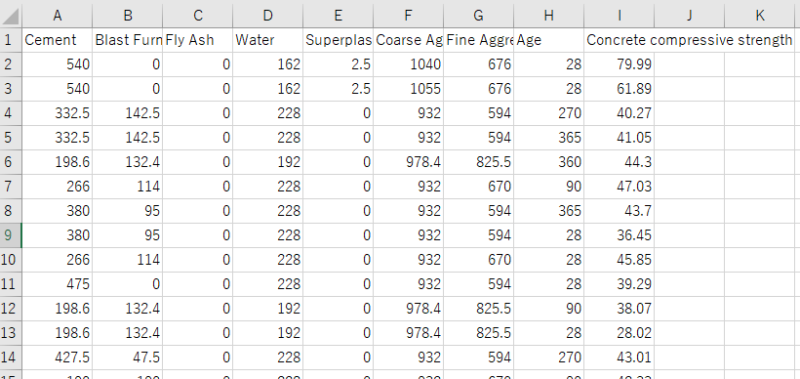
↑中身はこんな感じ。
| 説明変数 | cement : セメント(kg/㎥) Blast Furnance Slag : 高炉スラグ(kg/㎥) Fly Ash : フライアッシュ(kg/㎥) Water : 水(kg/㎥) Superplasticizer : 高流動化剤(kg/㎥) Coarse Aggregate : 粗骨材(kg/㎥) Fine Aggregate : 細骨材(kg/㎥) Age : 材齢(1〜365日) |
| 目的変数 | Concrete compressive strength : コンクリート圧縮強度(MPa) |
となっております。
目的変数とは求めたい値・知りたい値のことです。つまり”目的”となる変数。
説明変数とは目的変数の”理由”となるかも知れない値のこと。言い換えれば目的変数の”説明”になるかも知れない変数のことです。
機械学習でやりたいことは、材料の配合比率から何らかのパターンを見つけ出してコンクリート圧縮強度を予測することです。
つまり【説明変数を入れる→目的変数が出てくる】という仕掛け、つまり機械学習の【モデル】を構築するということですね。
環境確認
では、今回から使用していく開発環境の確認をしていきます。
正直Python3であれば問題ないと思います。ライブラリはあまりにも古いバージョンならアップデートしておきましょう。
前準備はここまで!次からは実際にCSVファイルをPythonで読み込んで機械学習を進めていきましょう!
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
そして世界に革命を起こすこと間違いなしの機械学習全自動化ライブラリ「PyCaret」の使用方法や、今後の社会を予想した
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
も同時発売中です。
「PyCaret」を使いこなせば、22種類もの機械学習手法と一気に比較したり、ブラックボックスであるモデル内部の解析までわずか10数行のコードで行うことができます!
中身はこんな感じ↓
- Pythonのインストール
- Anaconda「JupyterNotebook」の起動
- 仮想環境構築
- データセット
- 中身の確認
- PyCaretを実装する
- ライブラリのインポート
- データ型を推測させる
- モデルの構築
- モデルの選択
- ハイパーパラメータチューニング
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- 機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
Python初心者でもインストール~全自動ライブラリ実装・解析まで出来るようになります。
980円:11080文字の教科書になっています。
全自動でもいいからパッと機械学習を実装したい!
「PyCaret」のような最新技術を使いこなしたいな。
という方には非常にオススメです。是非一読あれ!
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
(教科書でのみ使うデータセット配布↓)

↓お次の記事

↓ 効率的なPython学習はオンラインスクールがオススメ ↓
コメント