
どうも、リンです。
今回も機械学習モデルを作っていきましょう。
前回までは決定木・ランダムフォレストを使って回帰をしていきました。


結果はこのようになりました。
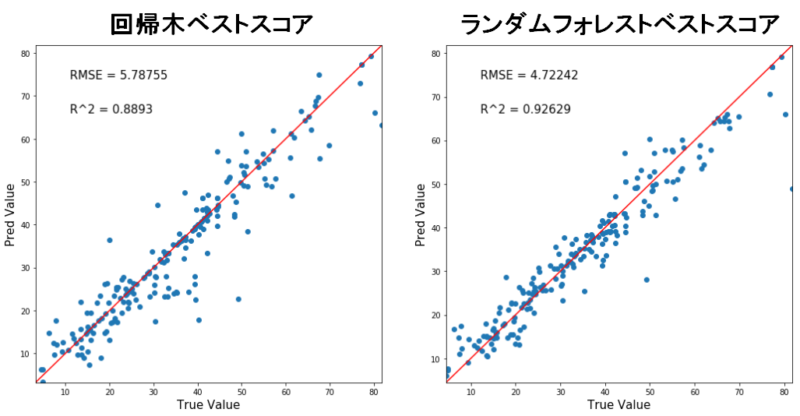
各モデルで予測値を出力し、正答値との相関マップを作りました。
横軸が正答値、縦軸が予測値なのでy=xの赤線に沿うほど正確予測ができるモデルとなります。
RMSEは小さいほど、R^2値は大きいほどGoodです。
つまり、ランダムフォレストの方が回帰木よりも精度の良いモデルになりましたね。
さぁ今回は新たな機械学習の手法「LightGBM」で回帰を行っていきましょう!
LightGBMとは?
概要
LightGBMとは決定木アルゴリズムを基に作られたアルゴリズムの一つです。
2016年に公開された機械学習の手法であり、スポンサーはなんと米マイクロソフト社です。
わずか数年前に公開されたアルゴリズムでありながら、データサイエンス界では非常に人気のある手法となっています。
競技プログラミングサイト「Kaggle」では、全世界の猛者が機械学習を用いた予測でランキングを競っております。
筆者も積極的に参加し、参加者とディスカッションをしておりますが、アルゴリズムの主流は「LightGBM or ニューラルネットワーク」となっています。
LightGBMは「世界トップレベルのデータサイエンティストが使う主砲」と言えるでしょう。
LightGBMの仕組み
LightGBMの仕組みを大雑把に説明します。(記事で説明し切るのは至難の業)
LightGBMの原理は非常に難解ですが、実装するのは簡単で結果を出せます。
よって、原理は正直知らなくてもある程度は問題が無いです。「こういうものなんか~」って気持ちで知っておいてくださいね。
ベースは決定木
LightGBMは「決定木」を基にしたアルゴリズムです。
決定木の仕組みは以前の記事で紹介しました。
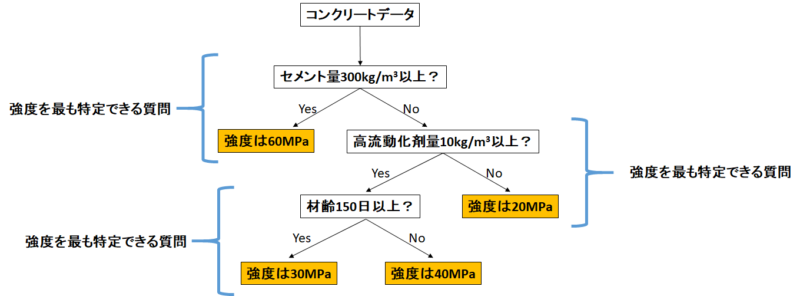
「決定木」とは「Yes or Noの質問」を繰り返すことでデータを分割する手法でした。
「Yes or Noの質問」は「データを最もよく分割する質問」とするように設計されており、
あり閾値を超えるとそこで分岐は終了するようになっています。
上の図では、連続した値を予測していることから「回帰木」というのが正確ですね。
弱学習器を統合する「アンサンブル学習」
LightGBMは「アンサンブル学習」と呼ばれる手法に該当します。
アンサンブル学習とは、いくつかの小さな機械学習モデル(悪く言うと1つだけでは精度の悪いモデル)をいくつも統合して一つのモデルにするという学習手法です。
これって、何か聞いたことある手法じゃないですかね?
そうです。前回紹介した「ランダムフォレスト」もアンサンブル学習なんです。
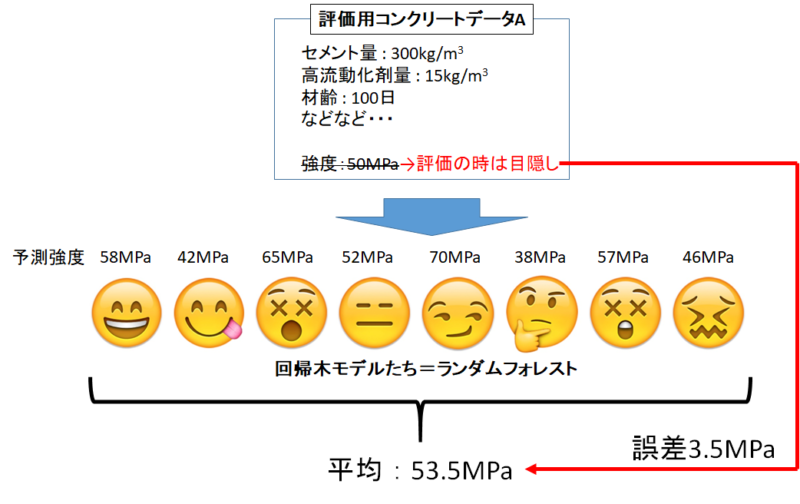
ランダムフォレストはいくつもの「性格が違う回帰木」を統合して一つのモデルにしていましたね。
LightGBMもこのように、様々な機械学習モデルを統合して一つのモデルを作っています。
誤差のバトンレース「勾配ブースティング」
LightGBMでは、「勾配ブースティング」を応用した計算を行っています。
勾配ブースティングとは何でしょうか?
イメージは下の図ですね。
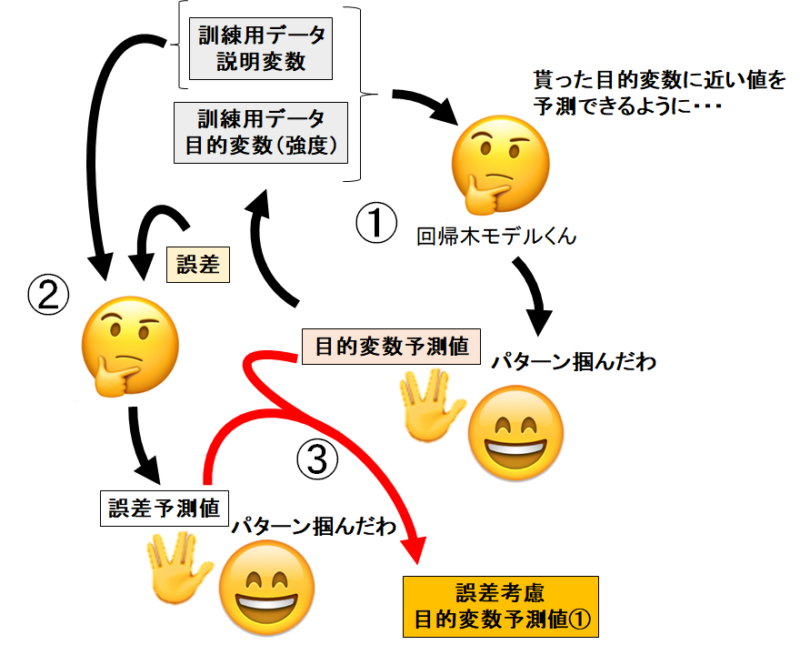
- 説明変数から目的変数(強度)を学習させ、強度の予測値を出す
- 予測値と正答値から誤差を計算
- 説明変数と誤差を学習させ、誤差予測値を出す
- 強度の予測値と誤差予測値を足して、誤差考慮した強度の予測値を出す
勾配ブースティングはこれだけでは終わりません。誤差考慮した強度の予測値から、また誤差を計算します。
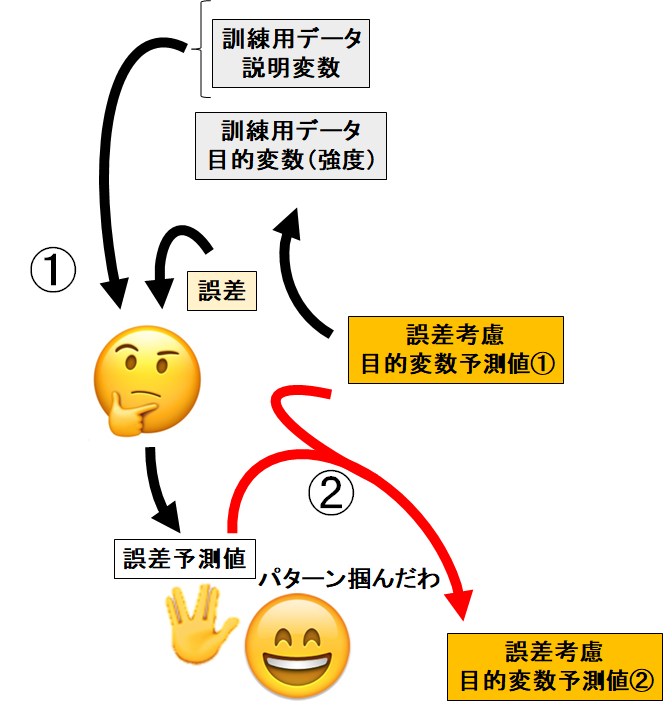
するとまた誤差予測値が出力され、誤差考慮した強度の予測値②が生まれます。
あとはこれの繰り返しで、どんどん誤差の予測値を生んでいけばいいわけです。
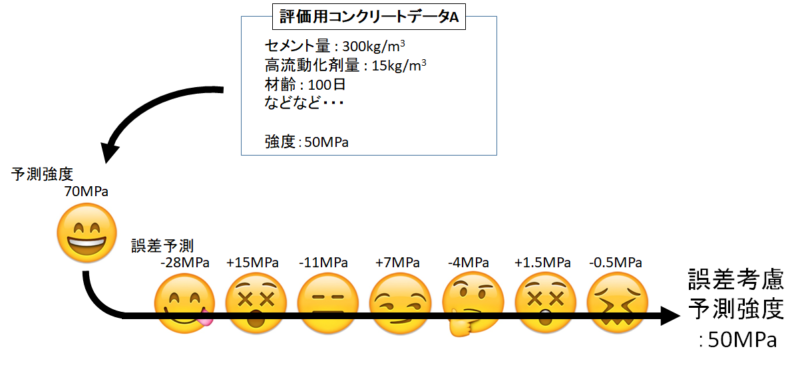
ある程度まで誤差の予測を繰り返したら、最初の予測強度と全ての誤差予測を足し合わせれば正答値にピタリと収束していきます。
実際に未知のデータを学習する際には、それぞれの回帰木が学習したパターンに沿って進んでいけば、強度と誤差の予測値を回帰してくれます。
全て足し合わせれば最終的な予測値として出力できますね。
ちなみに誤差予測値は「大きく予測を外したデータ」を優先して修正するアルゴリズムになっています。
LightGBMの工夫
LightGBMはアンサンブル学習の一つである勾配ブースティングを応用したアルゴリズムであると解説しました。
しかし、勾配ブースティングを利用したアルゴリズムは多数存在します。
ではLightGBMは他にどのような工夫を取り入れているのでしょうか?
Leaf-wiseな訓練過程
勾配ブースティングの決定木分岐過程には二つの種類があります。
- 「Level-wise」な分岐過程
- 「Leaf-wise」な分岐過程
それぞれのイメージは下の図の通り。
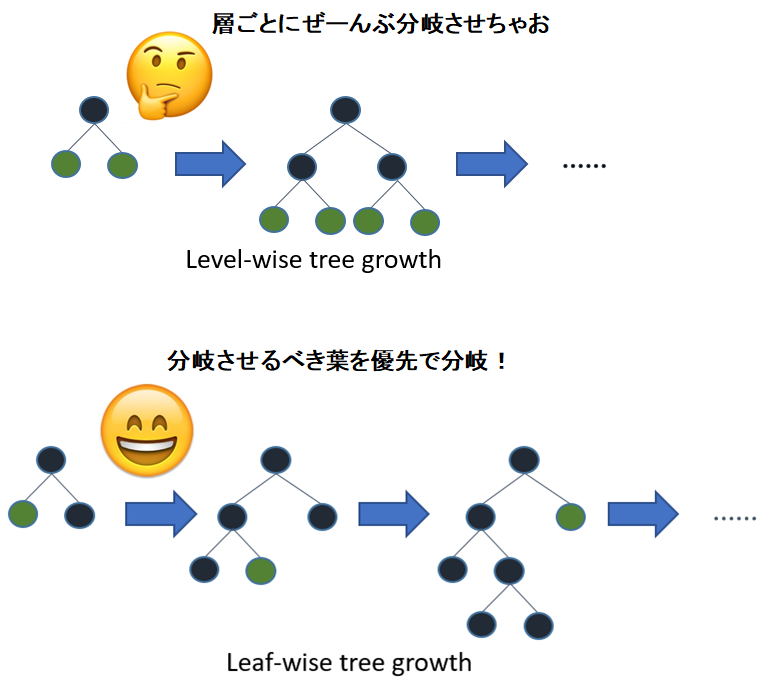
Leave-wiseは「層ごとに一括で」分岐を進めます。一つの層の分岐が全て終わるまでは次の層に行けません。
一方でLeaf-wiseは決定木を全体で見渡して、「分岐させるべき葉」を優先的に分岐させます。
一見Leaf-wiseの方が良さそうに見えますが、LightGBMがLeaf-wiseを採用しているだけであって、どちらが優勢なアルゴリズムってわけではありませんよ。
訓練データのヒストグラム化
さて非常に量の多いデータを扱う際にはモデルの構築に非常に時間がかかります。
計算量が多くなる原因の一つが、「全ての数値を参照するから」です。
ならば、データを簡易化してから計算させればある程度の精度を残したまま高速化できますね。
LightGBMでは、訓練データをヒストグラム化して計算を進めます。
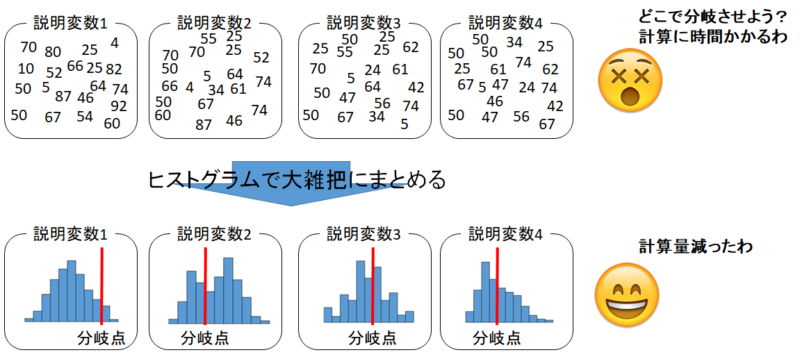
非常に細かい数値だったデータがヒストグラムにすることで「大雑把にまとめられた」データになります。
こうすることで高速でモデル構築を進めることができます。
ちなみに、どの程度大雑把なヒストグラムにするかは、統計的アプローチで最適化されています。
他にも様々な工夫がLightGBMには導入されておりますが、必要最低限知っておくべき知見はこの程度でしょう!
ガチで調べたい方は元論文でお調べください(手抜き)。
LightGBM: A Highly Efficient Gradient Boosting Decision Tree
実際にモデルを作って評価する
まあ理屈はここくらいで置いといて実装してみましょう。
最初からいきますよ。
ライブラリのインポート
1 2 3 4 5 6 7 8 9 10 11 12 13 | #データ解析用ライブラリ import pandas as pd import numpy as np #データ可視化ライブラリ import matplotlib.pyplot as plt import seaborn as sns #LightGBMライブラリ import lightgbm as lgb #訓練データとモデル評価用データに分けるライブラリ from sklearn.model_selection import train_test_split |
今回はLightGBMのライブラリもインポートします。
コマンドプロンプトで「pip install lightgbm」と打ち込んでインストールしておいてください。
Anacondaを使用している方はアナコンダプロンプトで「conda install -c conda-forge lightgbm」と打ち込んでインストールしてください。なんかこのコマンドが上手くインストールするコツらしい。
CSVファイルの取り込み
1 | concrete_data = pd.read_csv(r'C:\Users\concrete.csv', engine='python') |
例によって、コンクリートデータが入っているパスを入れてくださいね。
コンクリートデータを持っていない方は↓の記事からダウンロードしてください。
出来れば今までの記事を見ておくことをオススメします。

訓練用データとモデル評価用データに分割
1 | train_set, test_set = train_test_split(concrete_data, test_size=0.2, random_state=4) |
ここで、コンクリートデータを「訓練用」と「モデル評価用」に分けます。今回も8:2でいきましょう。
1 2 | print(len(train_set)) print(len(test_set)) |
訓練用データは824セット。モデル評価用データは206セットと表示されます。8:2ですね。
説明変数と目的変数に分割
1 2 3 4 5 6 7 | #訓練データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_train = train_set.drop('Concrete compressive strength', axis=1) y_train = train_set['Concrete compressive strength'] #モデル評価用データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_test = test_set.drop('Concrete compressive strength', axis=1) y_test = test_set['Concrete compressive strength'] |
前回の記事通り。イメージは下の感じですね。今回は回帰木モデルくんじゃなくてLightGBMくんですけどね!書き直すのがめんどくさい!(手抜き)
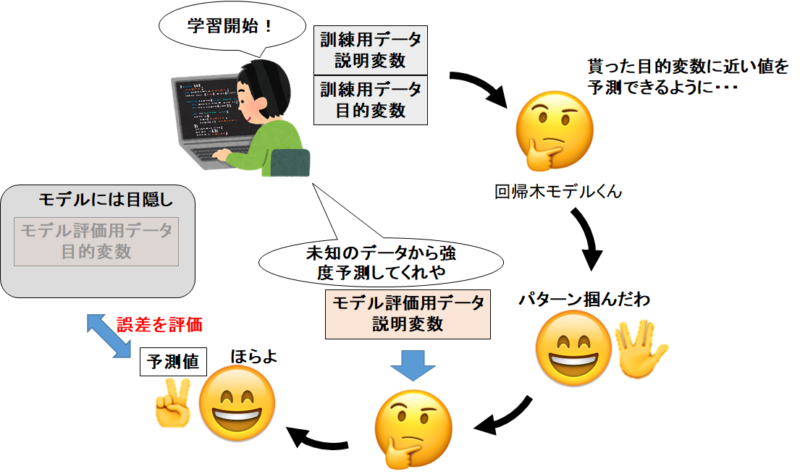
LightGBMのモデル構築
ではLightGBMのモデルを作っていきましょう。
その前の準備として、説明変数と目的変数を「LightGBM用のデータセット」に加工します。
1 2 | lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test) |
「LightGBM用のデータセット」にすることで、高速で計算を行えるようになります。
次に、LightGBMの挙動を決める”ハイパーパラメータ”を設定します。
1 2 | params = {'metric': 'rmse', 'max_depth' : 9} |
‘metric’は学習過程における評価基準です。通常通り、RMSE値が小さくなるほど正確な予測ができているとLightGBMに指示しています。
‘max_depth’ : 9は、学習過程の決定木の最大の深さを指定しています。
値が大きくなるほどより複雑な木となり、学習データと過剰にフィットする「過学習」を引き起こします。
今回は小手調べなのでハイパーパラメータはこの程度にしておきましょう。また後日チューニングをしましょう。
では学習を開始しましょう。
1 2 3 4 5 6 | gbm = lgb.train(params, lgb_train, valid_sets=lgb_eval, num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50) |
またややこしいコードになりましたね。詳しく説明します。
lgb.train()で学習を開始できるのですが、色々便利な機能を追加できます。
第一引数の「params」で、先ほど指定したハイパーパラメータを入れることができます。
第二引数には「lgb_train」とあります。訓練データはlgb_trainだと指定しています。
第三引数のvalid_sets=lgb_evalは、モデル評価用データを与えています。後述しますが、「あーリーストッピング」という機能を使う上でモデル評価用データが必要ですのでここで記述しています。
第四引数のnum_boost_round=10000は、学習を10000サイクル繰り返せという指示です。後述しますが、あえて過剰な量のサイクル数を与えています。
第五引数のearly_stopping_rounds=100は後述で詳しく説明しましょう。
第六引数のverbose_eval=50は学習過程を50サイクルずつ表示してくれます。
アーリーストッピングとは?
LightGBMは学習のサイクル数を増やすごとに、より訓練データにフィットするモデルを作っていきます。
聞こえは良さそうですが、実は訓練データにフィットしすぎると問題が生じます。
学習サイクル数を増やすと、訓練データとモデル評価用データの予測値ー正答値誤差は下の図のように乖離していきます。
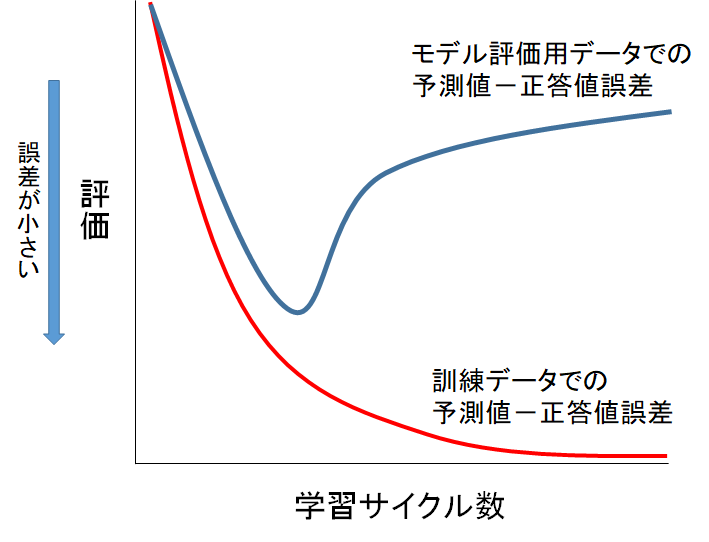
なぜこのような現象が起きるのでしょうか?
形式的に、説明変数が一つだけのデータでLightGBMモデルを作るとしましょう。
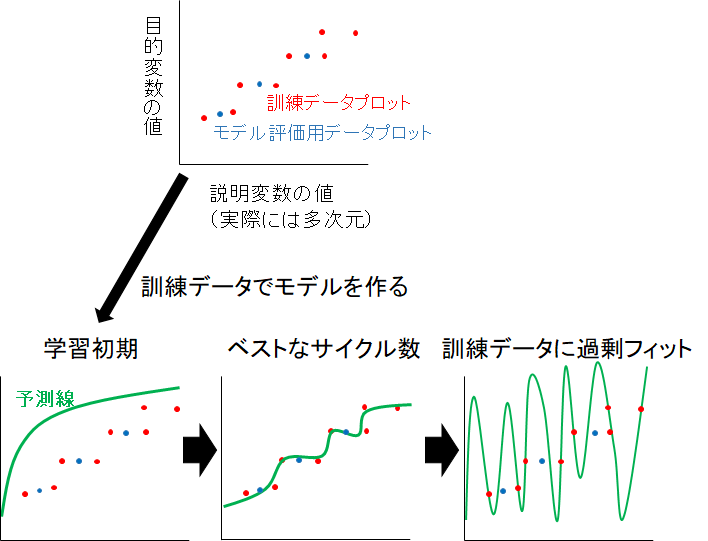
学習初期(学習サイクル数が小さい時期)は、訓練データから学習が進んでおらず、まともな予測が出来ていません。
ベストな学習時期になると、訓練データの学習が進むことで、モデル評価用データの予測も延長線上で上手くいきます。(モデル評価用データは学習には関与していないが、モデルが訓練データにフィットする延長で予測ができる)
ベストな学習時期を超えると、モデルは訓練データのみにフィットし、モデル評価用データはまともに予測できなくなってしまいます。
先ほどの図を交えるとこんな感じになります。
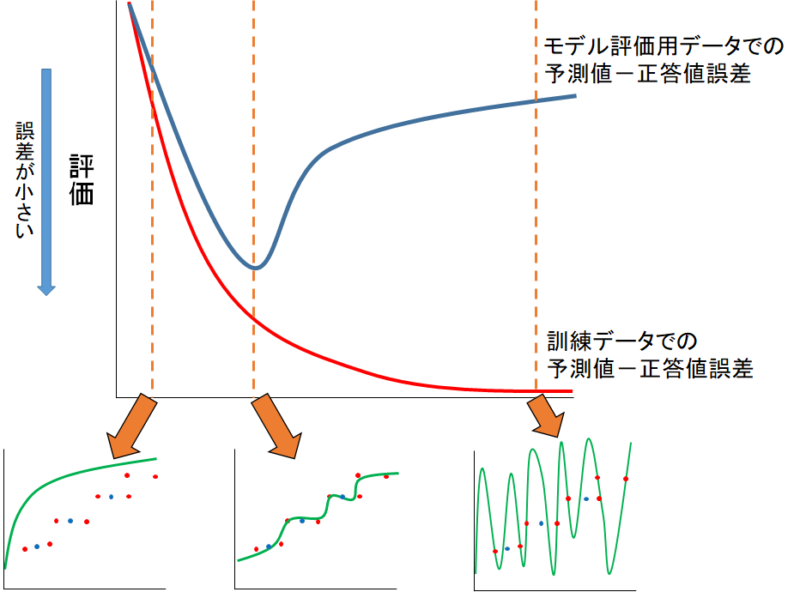
学習サイクル数を増やすと過剰フィットになるなら、モデル評価用データの予測値ー正答値誤差が最小になる点で学習を止めたいですよね。
それがアーリーストッピングです。
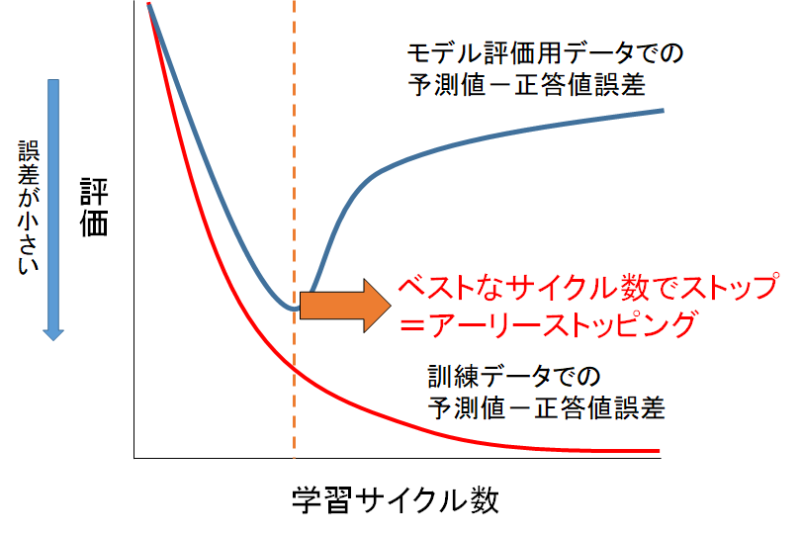
LightGBMにはこのアーリーストッピングの機能が付いています。
先ほどのコードを思い出しましょう。
1 2 3 4 5 6 | gbm = lgb.train(params, lgb_train, valid_sets=(lgb_train, lgb_eval), num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50) |
第四引数のnum_boost_round=10000は、学習を10000サイクル繰り返せという指示ですが、アーリーストッピングのおかげでベストな学習サイクル数でストップします。だから多めの数にしているのです。
第五引数のearly_stopping_rounds=100は「100サイクル分くらいは観察して、過学習しているようならベストなサイクル数を選択して学習を終わらせろ」という指示ということですね。
長くなりましたが、アーリーストッピングの説明は以上です。
予測を出力する
1 2 3 4 5 6 | gbm = lgb.train(params, lgb_train, valid_sets=lgb_eval, num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50) |
先ほどのコードを実行すると、次のような出力がされます。
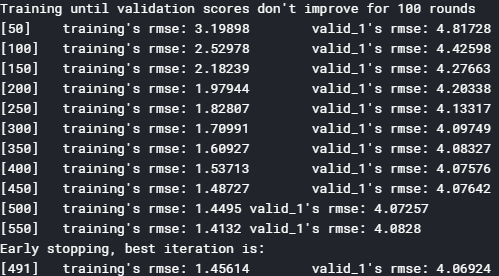
左が訓練用データでの予測値ー正答値の誤差評価。右がモデル評価用データでの予測値ー正答値の誤差評価です。
verbose_eval=50としたように、50サイクル毎に学習過程が表示されていますね。
そして最終行!491サイクル目がベストなスコアとして表示されています。
ではモデル評価用データをもう一度予測してもらい可視化しましょう。
1 | predicted = gbm.predict(X_test) |
モデル評価用データの説明変数をgbm(訓練済みのモデルが入っている箱)に入れて、予測値をpredictedに入れます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #関数の処理で必要なライブラリ from sklearn.metrics import mean_squared_error from sklearn.metrics import r2_score #予測値と正解値を描写する関数 def True_Pred_map(pred_df): RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) R2 = r2_score(pred_df['true'], pred_df['pred']) plt.figure(figsize=(8,8)) ax = plt.subplot(111) ax.scatter('true', 'pred', data=pred_df) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') plt.text(0.1, 0.9, 'RMSE = {}'.format(str(round(RMSE, 5))), transform=ax.transAxes, fontsize=15) plt.text(0.1, 0.8, 'R^2 = {}'.format(str(round(R2, 5))), transform=ax.transAxes, fontsize=15) |
可視化の関数です。
1 2 | pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] |
可視化の関数にぶち込めるように、モデル評価用データの予測値と正答値を加工して一つのデータフレームにします。
1 | pred_df.head() |

中身はこんな感じです。1列目に正答値、2列目に予測値です。
1 | True_Pred_map(pred_df) |
では可視化しましょう!!!
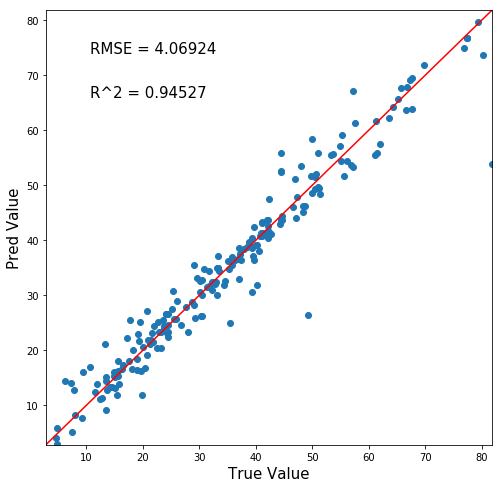
めちゃ性能いいじゃないすかぁ
横軸が正答値で、縦軸が予測値なのでy=xの赤線に沿うほど正確な予測ができているということです。
ハイパーパラメータのチューニングもしてないのにこのレベル!
今までのモデルと見比べてみましょうか。
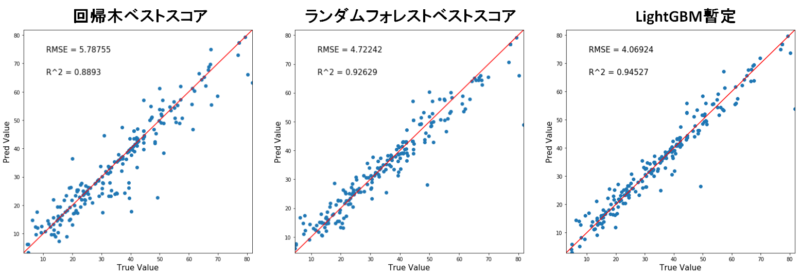
うーん。素晴らしい精度です。
特徴量重要度を表示する
さて、LightGBMでもランダムフォレスト同様に特徴量の重要度を表示できます。
コードはたったの一行!すばらしい機能です!
1 | lgb.plot_importance(gbm, height=0.5, figsize=(8,16)) |
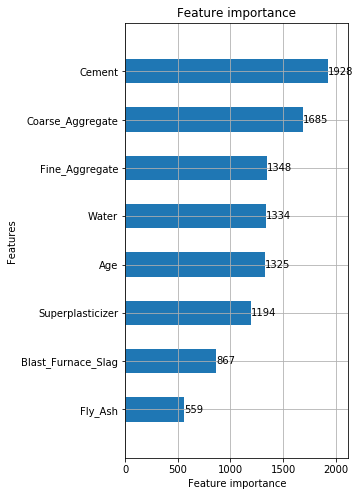
ふーむ。ランダムフォレストではセメント・材齢が重要と判断されましたが、LightGBMではセメント・粗骨材が重要らしいですね。
アルゴリズムが違うので、もちろん重要度は変化しますよ。
特徴量重要度とは「そのアルゴリズムにおいて」予測に重要だった特徴量を高く評価します。
絶対的に信頼できるモノでもありませんね。
ハイパーパラメータを気持ち程度に動かしてみる
ハイパーパラメータの”max_depth”はテキトーに9にしていたので、動かしたときの精度の変化を見てみましょうか。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | RMSE_list = [] count = [] for i in range(1, 15): params = {'boosting_type': 'gbdt', 'objective': 'regression', 'metric': 'rmse', 'max_depth' : i} gbm = lgb.train(params, lgb_train, num_boost_round=10000, valid_sets=lgb_eval, early_stopping_rounds=100, verbose_eval=50) predicted = gbm.predict(X_test) pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) RMSE_list.append(RMSE) count.append(i) |
“max_depth”(学習過程の木の最大深さ)を1~14まで変化させた時のモデル評価用データ誤差RMSE値を記録しておくコードです。
RMSE_listに格納されていきます。
1 2 3 4 5 6 | plt.figure(figsize=(16,8)) plt.plot(count, RMSE_list, marker="o") plt.title("RMSE Values", fontsize=30) plt.xlabel("max_depth", fontsize=20) plt.ylabel("RMSE Value", fontsize=20) plt.grid(True) |
そして可視化のコードです。
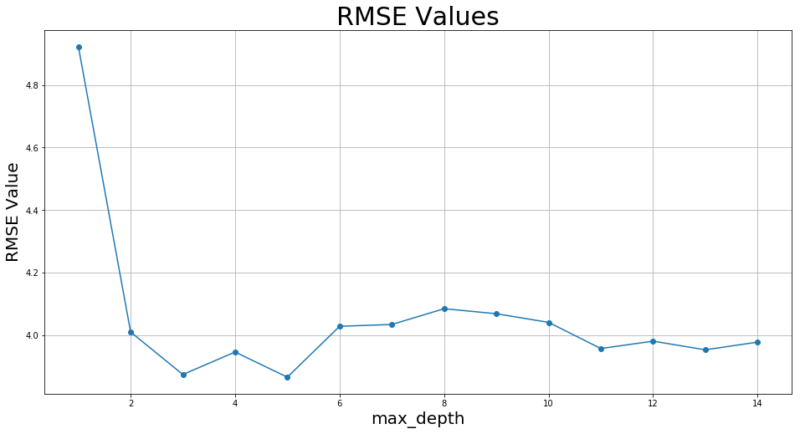
最大深さは3くらいで頭打ちですね。「最大」なので深さ4以上の木になることがそもそもあまりないのでしょうか?
まとめ
ということで、今回はLightGBMの原理と実装をかるーくやっていきました。
次の記事では、ハイパーパラメータのチューニングをしてどの程度精度を上げることができるのかを見てみましょう!
では!
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
そして世界に革命を起こすこと間違いなしの機械学習全自動化ライブラリ「PyCaret」の使用方法や、今後の社会を予想した
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
も同時発売中です。
「PyCaret」を使いこなせば、22種類もの機械学習手法と一気に比較したり、ブラックボックスであるモデル内部の解析までわずか10数行のコードで行うことができます!
中身はこんな感じ↓
- Pythonのインストール
- Anaconda「JupyterNotebook」の起動
- 仮想環境構築
- データセット
- 中身の確認
- PyCaretを実装する
- ライブラリのインポート
- データ型を推測させる
- モデルの構築
- モデルの選択
- ハイパーパラメータチューニング
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- 機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
Python初心者でもインストール~全自動ライブラリ実装・解析まで出来るようになります。
980円:11080文字の教科書になっています。
全自動でもいいからパッと機械学習を実装したい!
「PyCaret」のような最新技術を使いこなしたいな。
という方には非常にオススメです。是非一読あれ!
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
↓こんな記事見てるド変態データサイエンティスト(誉め言葉)にピッタリのスクール↓

↓他にもおすすめのスクールあります↓
↓機械学習人材は転職が簡単です。登録しておいてよかった↓

次の記事↓

【参考書籍】
テーブルデータでの機械学習手法が綺麗にまとめられています。
機械学習競技サイト「Kaggle」のトッププレイヤー達が共同著者です。とってもオススメ。
↓ 書評 ↓

↓ この辺の記事も見とくと良いかもよ ↓


コメント
はじめまして。大変わかりやすい記事でしたが1つ疑問点があったためコメントさせていただきます。
「LightGBMのモデル構築」の項のパラメーターの説明において
>第二引数には「lgb_train」とあります。訓練データとモデル評価用データの”説明変数”が格納されていましたね。「説明変数はこれだぞ!」と指定しているわけです。
>第三引数のvalid_sets=(lgb_train, lgb_eval)は、説明変数セットと目的変数セットをひとまとまりにして与えています。「説明変数と目的変数をあげるから、これで学習してね」ってことですね。
とありますが、第2引数は「訓練データの説明変数と目的変数」、第3引数は「訓練データと評価用データの組」の誤りではないでしょうか?
コメントありがとうございます。
確認したところ、コードと説明が誤っておりました。。。
長い記事なので、執筆中に脳死状態になっていたのが原因ですね。
記事を修正致しました!今後ともより質の良い記事の為にご協力よろしくお願いします!