
どうも、リンリンです。
前回の記事ではハイパーパラメータ自動チューニングライブラリ「Optuna」を使って、ハイパーパラメータチューニングをしていきました。

無事、モデルの精度を上げることに成功しましたね!
今回も機械学習における「不満」を解決するためにコードを書いていきましょう!!
【参考書籍】
テーブルデータでの機械学習手法が綺麗にまとめられています。
機械学習競技サイト「Kaggle」のトッププレイヤー達が共同著者です。とってもオススメ。
↓ 書評 ↓

現状に対する不満「モデル評価用データが少ない」
さて、今まで様々な機械学習モデルを使って予測をしました。
でも私はかなり不満に思っている部分があります。それは…
モデル評価用データ206セットって少なくない!?!?!!?!?
って話ですよ。

これは許せん。20%だけで評価していて、本当にいいのでしょうか??
モデル評価用データの割合を大きくする?
「20%が少ないと思うなら40%にすればいいじゃないか」と言われると、それもどうかと思います。
だって機械学習モデルを作る80%のデータが60%に減ってしまうじゃないですか。
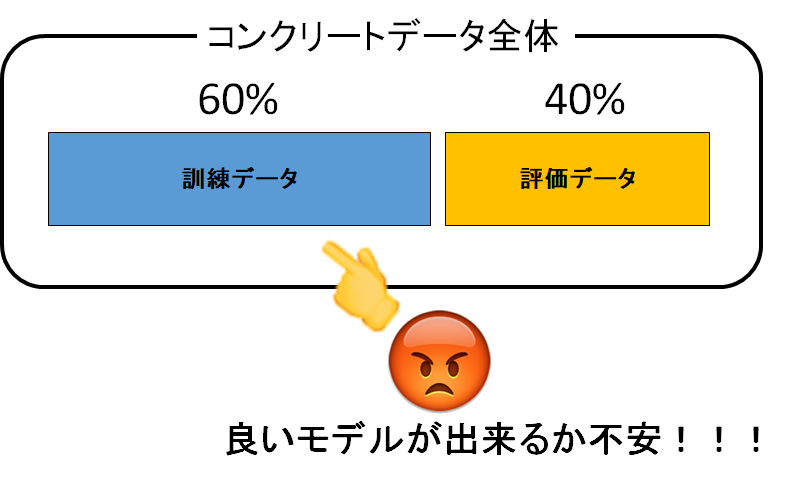
それでは機械学習モデルがデータ不足によって精度の悪いモノになってしまいそうですね。
じゃあ一体どうすれば!?
解決策:交差検証
答えは「交差検証」です。
交差検証とは、データを複数に分割して、1つのグループを評価データ・その他のデータを訓練データとしてモデルを構築・評価する手法です。
イラストで説明しましょうか。
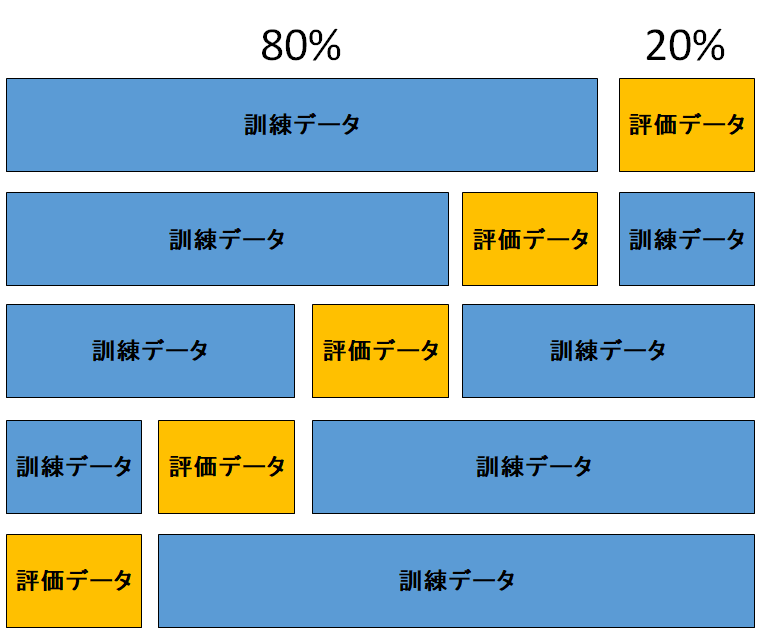
まずは訓練データを80%・評価データを20%に分けます。評価データの重複を許さないように、5種類の分割が考えられますね。
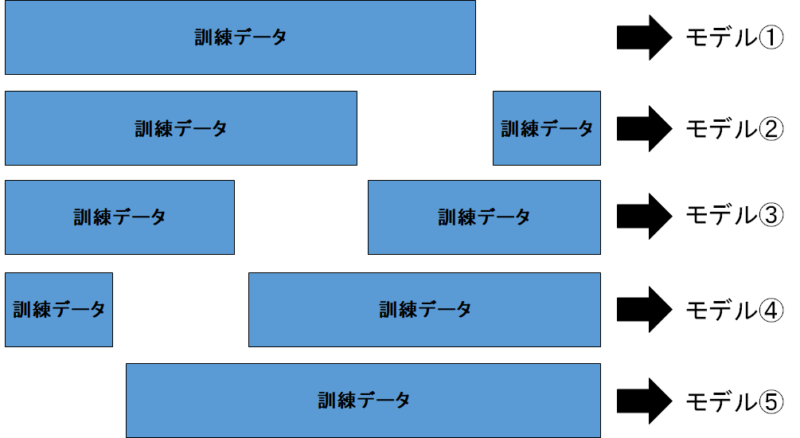
そして次に評価データを隠して、訓練データを使って機械学習モデルが作られます。
モデルが出来たら、先ほど隠していた評価データをモデルに入れれば、予測値を出してくれます。
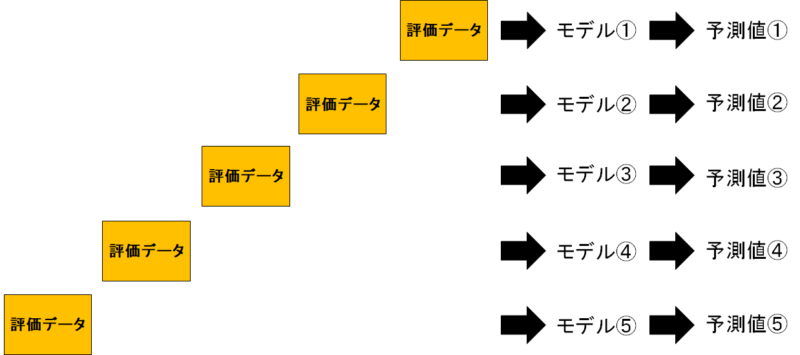
評価データの重複を許していないんでしたね。つまり、予測値を全て統合すれば「全データの予測値を出力できる」ということです!
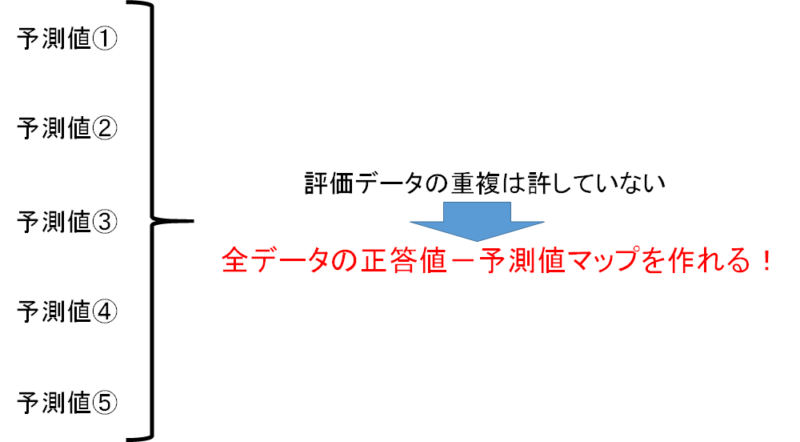
ん?ちょっとまって。
じゃあ最初から「全部を訓練データかつ評価データにすればいいじゃん」と思った方は惜しいですね。
以前の記事を思い出しましょう。

機械学習モデルは訓練データには過剰にフィットしているので、訓練データを評価データに転用するのはNGでしたよね。不当に高い評価を出してしまいます。
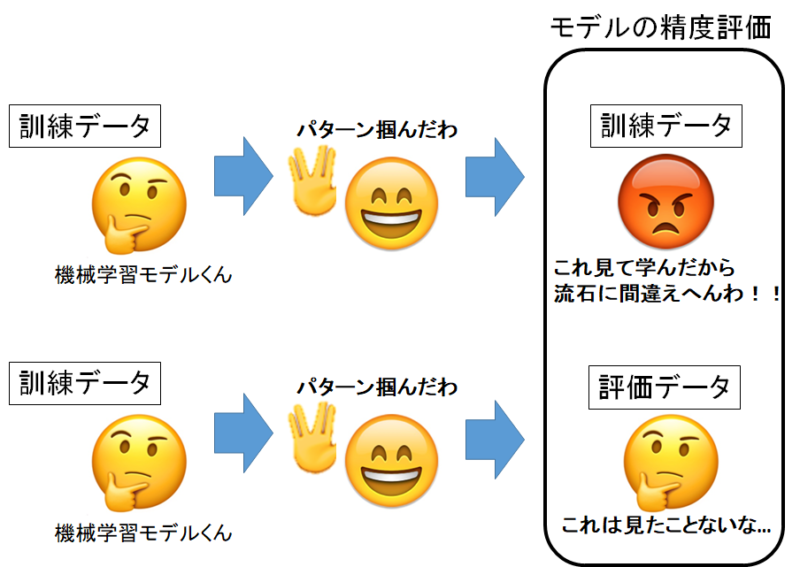
だからわざわざデータを分割して、訓練データと評価データに分ける必要があったんですよね。
コードを書いて実践してみる
それでは実際にコードを書いて交差検証を実行しましょう。
ライブラリのインポート
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | #データ解析用ライブラリ import pandas as pd import numpy as np #データ可視化ライブラリ import matplotlib.pyplot as plt import seaborn as sns #ランダムフォレストライブラリ import lightgbm as lgb #交差検証用に訓練データとモデル評価用データに分けるライブラリ from sklearn.model_selection import KFold #関数の処理で必要なライブラリ from sklearn.metrics import mean_squared_error from sklearn.metrics import r2_score |
今回は交差検証用にsckit-learnのKFoldというパッケージをインポートします。
それ以外は前回の記事と同様ですね。
CSVファイルの取り込み
1 | concrete_data = pd.read_csv(r'C:\Users\concrete.csv', engine='python') |
例によって、コンクリートデータが入っているパスを入れてくださいね。
コンクリートデータを持っていない方は↓の記事からダウンロードしてください。
出来れば今までの記事を見ておくことをオススメします。

可視化関数の導入
後々、予測値と正答値を可視化するので関数を導入しておきます。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #予測値と正解値を描写する関数 def True_Pred_map(pred_df): RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) R2 = r2_score(pred_df['true'], pred_df['pred']) plt.figure(figsize=(8,8)) ax = plt.subplot(111) ax.scatter('true', 'pred', data=pred_df) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') plt.text(0.1, 0.9, 'RMSE = {}'.format(str(round(RMSE, 5))), transform=ax.transAxes, fontsize=15) plt.text(0.1, 0.8, 'R^2 = {}'.format(str(round(R2, 5))), transform=ax.transAxes, fontsize=15) |
今までの記事で使っていた関数なので、もう慣れましたかね。
ハイパーパラメータを指定
LightGBMの挙動を変えるパラメータでも、「人の手を付けるべきパラメータ」を「ハイパーパラメータ」と言います。
今回は前回の記事で導き出したハイパーパラメータを使いましょう。
1 2 3 4 5 6 7 8 9 | params = {"metric": 'rmse', "max_depth" : 9, "subsumple" : 0.852102444399488, "subsample_freq" : 0, "leaning_rate" : 0.012973664715902685, "feature_fraction" : 0.6606677298772056, "lambda_l1" : 0.05523842390838453, "lambda_l2" : 0.24079410098503487 } |
前回の記事↓
交差検証を実行
では交差検証をしていきましょう。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | #kf : データ分割の挙動を指定する箱。今回は5分割・データシャッフルあり。 kf = KFold(n_splits=5, shuffle=True, random_state=1) #predicted_df : これから各予測値を結合していく時に、空のデータフレームを容易しておく predicted_df = pd.DataFrame({'index':0, 'pred':0}, index=[1]) #交差検証5分割で行うので、5回ループが繰り返される。 #kfにコンクリートデータのindexを与え、訓練データindexと評価データindexを決定してもらう。 for train_index, val_index in kf.split(concrete_data.index): #訓練データindexと評価データindexを使って、訓練データと評価データ&説明変数と目的変数に分割 X_train = concrete_data.drop('Concrete compressive strength', axis=1).iloc[train_index] y_train = concrete_data['Concrete compressive strength'].iloc[train_index] X_test = concrete_data.drop('Concrete compressive strength', axis=1).iloc[val_index] y_test = concrete_data['Concrete compressive strength'].iloc[val_index] #LightGBM高速化の為のデータセットに加工する lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test) #LightGBMのモデル構築 gbm = lgb.train(params, lgb_train, valid_sets=(lgb_train, lgb_eval), num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50) #モデルに評価用説明変数を入れて、予測値を出力する predicted = gbm.predict(X_test) #temp_df : 予測値と正答値を照合するために、予測値と元のindexを結合 temp_df = pd.DataFrame({'index':X_test.index, 'pred':predicted}) #predicted_df : 空のデータフレームにtemp_dfを結合→二周目以降のループでは、predicted_df(中身アリ)にtemp_dfが結合する predicted_df = pd.concat([predicted_df, temp_df], axis=0) |
いやごめんなさい。難しいコードになっちゃいました。
これでもかっ!ってほど注釈を入れたのですが、分かりづらい点が多いですよね。
ちょっとイラスト付きで解説しますね。
まず「何でkfにコンクリートデータindexを与えているか」ですね。
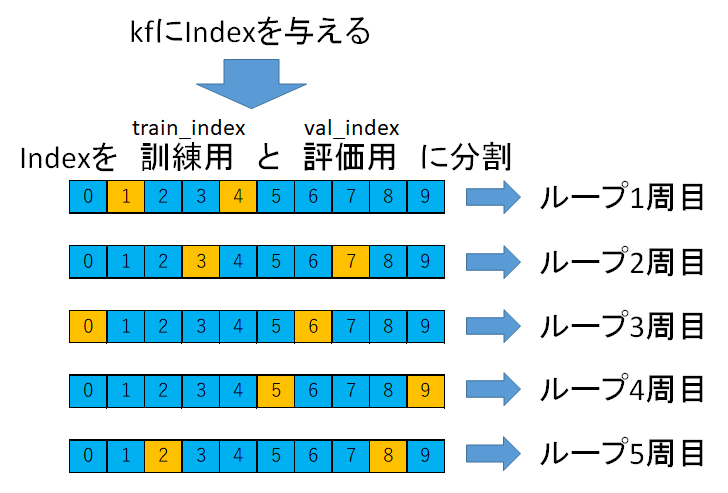
状態としては上の図のように、Indexを訓練用(青色)と評価用に(オレンジ)に分割してそれぞれのループで使用しています。
例えばループ1周目では、Index1と4が評価データIndexとなっていますね。
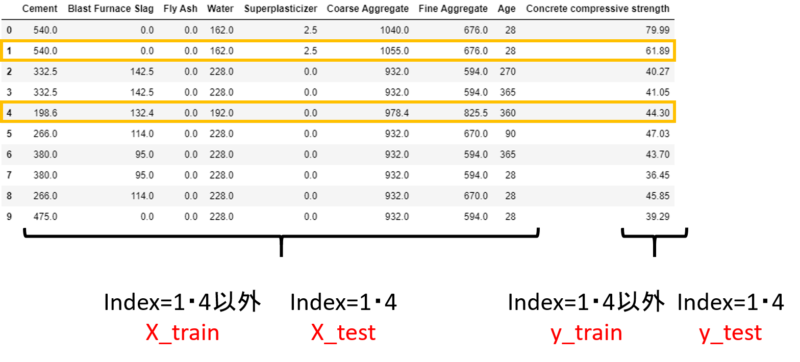
訓練データと評価データのIndexが分かれば、説明変数と目的変数を分割することもできます。
実際にはindexは0~9だけではなく、0~1029まで(コンクリートデータ数分)ありますが、このようにしてX_train, X_test, y_train, y_testを作るわけです。
そしてコードで分かりづらい箇所がpredicted_dfですね。
1 | predicted_df = pd.DataFrame({'index':0, 'pred':0}, index=[1]) |
この箇所では、次のように空のデータフレームが作られています。

そしてループの中のコード
1 | temp_df = pd.DataFrame({'index':X_test.index, 'pred':predicted}) |
で、temp_dfの中身は
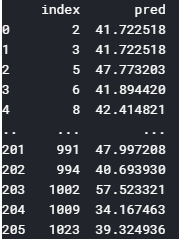
このようにindex列に予測値を作り出した評価データのindexが。pred列には予測値が格納されています。
1 | predicted_df = pd.concat([predicted_df, temp_df], axis=0) |
そしてこのコードで、空のデータフレームとtemp_dfを結合します。
ということで、最終的に作られたpredicted_dfがこちら。
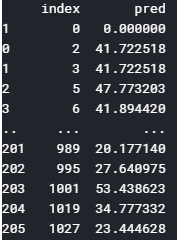
このままでは色々と不備がありますね。
- 1行目に空のデータ(index=0, pred=0.00000)が入っている
- 正答値が格納されていない
- indexが’index’という列に表記されているだけで、データフレームとしてのindexになっていない
ということで、これらの不備を解決するためにまた加工をします。
1 2 | predicted_df = predicted_df.sort_values('index').reset_index(drop=True).drop(index=[0]).set_index('index') predicted_df = pd.concat([predicted_df, concrete_data['Concrete compressive strength']], axis=1).rename(columns={'Concrete compressive strength' : 'true'}) |
このコードを実行すると、predicted_dfはこんな感じになります。
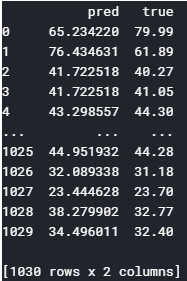
はい。空のデータが消え、正答値も格納され、’index’列はデータフレームとしてのindexになりました。
今回はこんな分かりづらいコードになってしまいました。もっと強い方に可読性の高い記述方法がないか聞きたいですね。
予測値と正答値を可視化
ではさっそく交差検証で算出された全データの予測正答値マップを出力しましょう!
1 | True_Pred_map(predicted_df) |
さっきの関数に作ったpredicted_dfをぶち込みます。
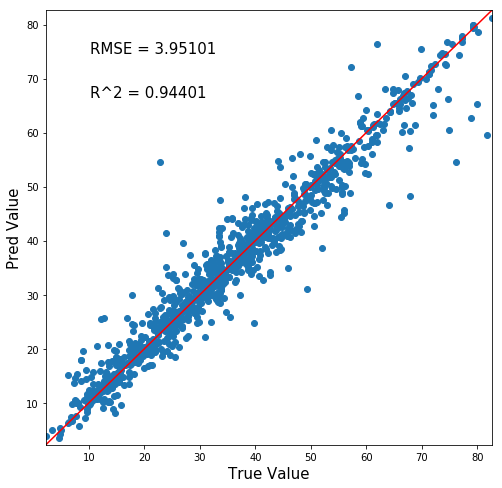
素晴らしい!全データ分のプロットがあるだけに密な相関図になっています!
ちなみに前回は↓ データ数は1/5ですね。
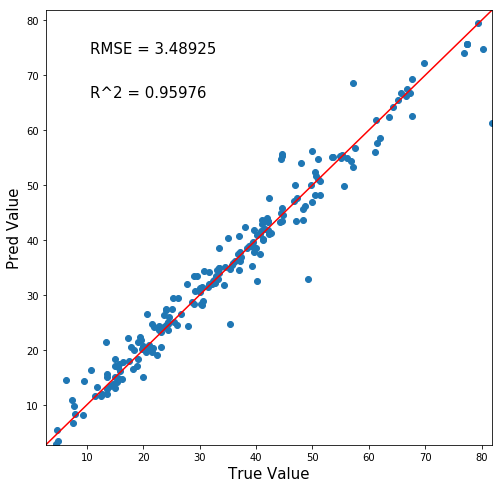
ということで、交差検証をすることでモデルの精度を落とすことなくより多くの予測値を作り上げることができました!
このような交差検証は、モデルを正確に評価する上で非常に重要なテクニックになります。
交差検証のイメージを忘れずに覚えておきましょう。
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
コメント