
どうも、リンです。
前回は探索的データ解析(EDA)でデータセットの構造理解をしていきました。


では、実際に機械学習のモデルを作って、予測をしていきましょう。
今回は機械学習の手法の一つである「決定木」のモデルを作っていきます。
決定木とは?
決定木とは、数ある機械学習の手法の一つで、分かりやすく言うと「Yes or Noでデータを分けていく」手法です。
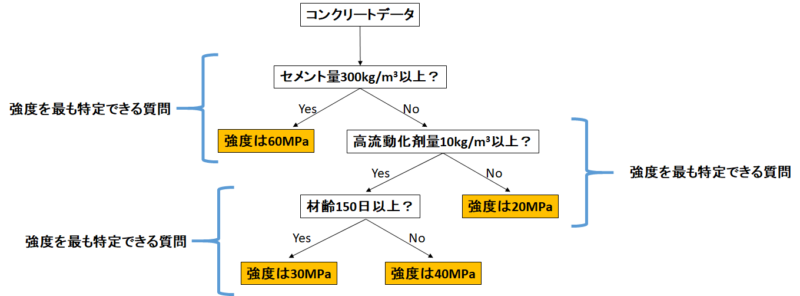
今回で言うと、目的変数であるコンクリート圧縮強度を最も特定できる質問を数式で選択します。
(詳細はエントロピーの数式を用いて、「最もよくデータを分割する質問」が選択されます。詳しくは数式が立ち並ぶ記事を探してください。)
質問に対して「Yes or No」でデータが分割されていき、分割の具合がある閾値まで行けば「強度は○○MPa」と予測します。
今回は「連続した数値を予測」しているので「回帰木」と呼ばれます。
モデルの評価をどうするのか?
さて、コンクリートデータでモデルを作ったとするとモデルの「評価」はどうするのでしょうか?
「評価」とは「このモデルはどのくらい正確にコンクリート強度を予測できるのか」ということです。
もしもコンクリートデータ全てを使って回帰木モデルを作り、そのままコンクリートデータでモデルの正確性を評価するとどうなるでしょうか?
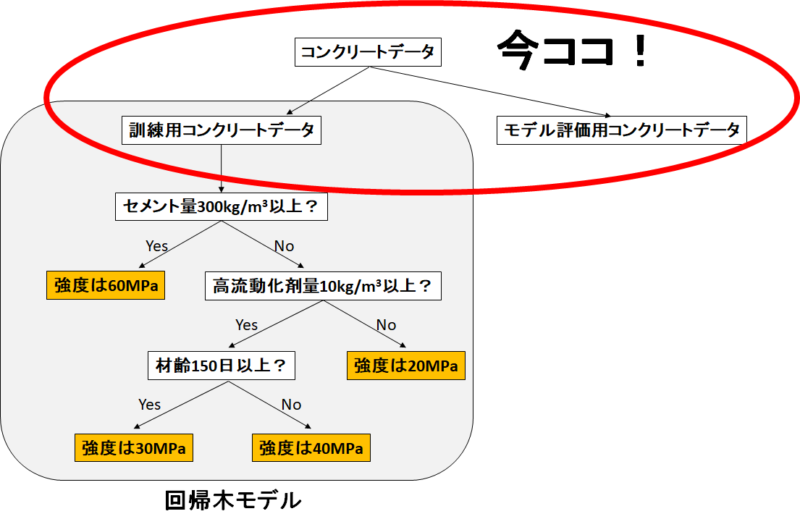
下の図を見てください。
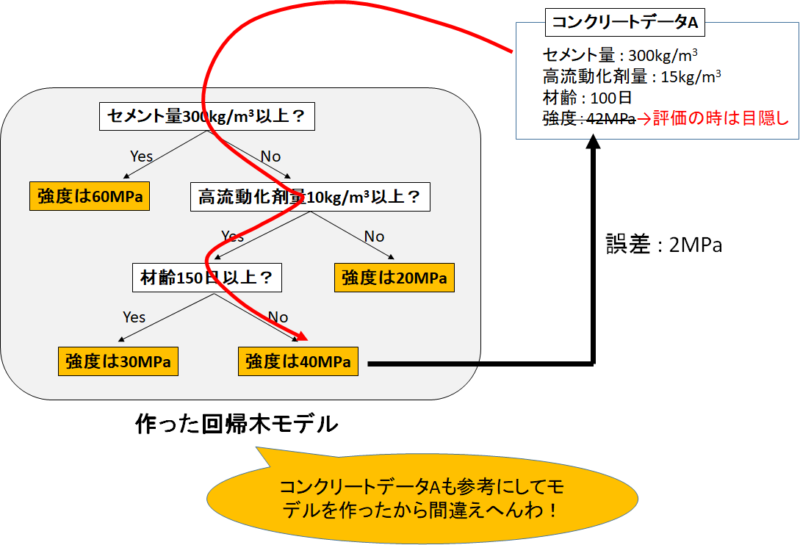
評価するために目的変数である「強度」を目隠ししてモデルに渡しても、
モデルは「これさっき見たわ!」と強度を予測してくるわけです。
これではただの「カンニング専門モデル」を評価することになってしまいます。
私たちは「未知のコンクリートデータから強度を予測するモデル」を作りたい。
つまりこうするんです。
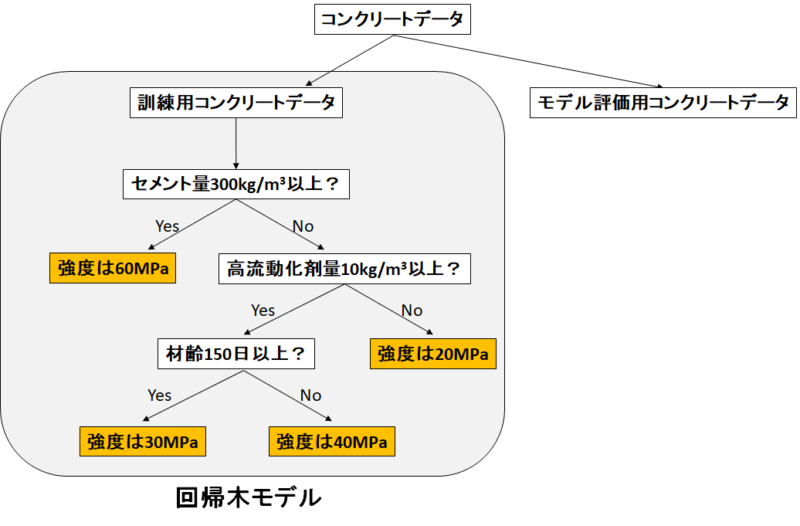
コンクリートデータを「訓練用」と「モデル評価用」に分けます。
「訓練用」を使ってモデルを作り、「モデル評価用」で予測と目的変数の誤差を評価します。
するとどうなると思いますか?
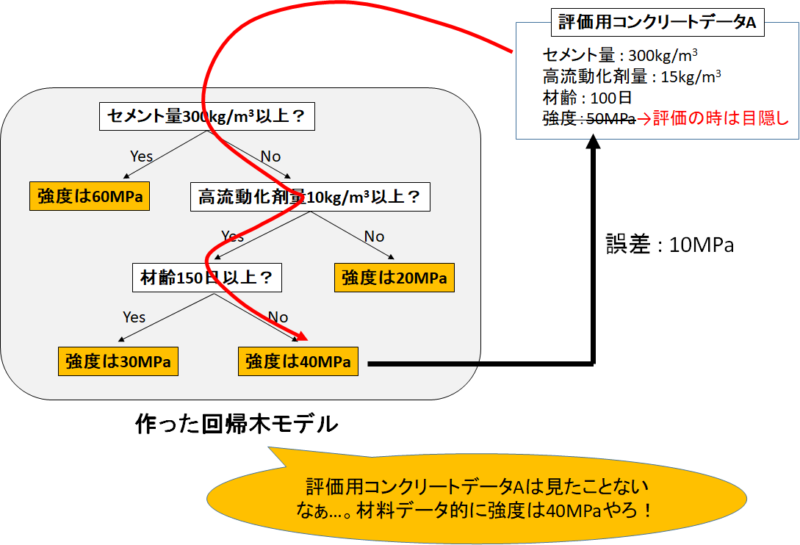
機械学習モデルは今までに見たことがないデータを渡されることになりますので、
「未知のコンクリートデータから強度を予測するモデル」として評価ができます。
必然的に「カンニング専門モデル」より誤差は大きくなりますが、それでいいんです。
「テストの答えを盗んで予習してきた学生A君」と「未知のテストに実力で挑むB君」なら、A君の方が点数が高くなります。しかし私たちが求めるのは学力の高い学生ですから、カンニングは許しません(分かりづらい)
実際にモデルを作って評価する
さて、御託はいいからさっさとコードを見せろやと。分かってますよ(泣)
ほんじゃあ、探索的データ解析で余分な特徴量とか作っちゃいましたし、最初からいきましょう。
ライブラリのインポート
1 2 3 4 5 6 7 8 9 10 11 12 13 | #データ解析用ライブラリ import pandas as pd import numpy as np #データ可視化ライブラリ import matplotlib.pyplot as plt import seaborn as sns #決定木ライブラリ from sklearn import tree #訓練データとモデル評価用データに分けるライブラリ from sklearn.model_selection import train_test_split |
まずはライブラリのインポート。決定木モデルを作るライブラリとか、訓練データとモデル評価用データに分けるライブラリも追加しておきました。
もしお使いの環境にインストールしていないライブラリがあれば、「pip install ○○」とか「conda install ○○」で入れてくださいな。言ってる意味分からなければググってください。(手抜き)
CSVファイルの取り込み
1 | concrete_data = pd.read_csv(r'C:\Users\concrete.csv', engine='python') |
そして、コンクリートデータの取り込み。コンクリートデータが入っているパスを入れてくださいね。
訓練用データとモデル評価用データに分割
1 | train_set, test_set = train_test_split(concrete_data, test_size=0.2, random_state=4) |
ここで、コンクリートデータを「訓練用」と「モデル評価用」に分けます。今回は8:2にします。
1 2 | print(len(train_set)) print(len(test_set)) |
訓練用データは824セット。モデル評価用データは206セットと表示されます。
コンクリートデータを8:2で分割することができましたね。
説明変数と目的変数に分割
1 2 3 4 5 6 7 | #訓練データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_train = train_set.drop('Concrete compressive strength', axis=1) y_train = train_set['Concrete compressive strength'] #モデル評価用データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_test = test_set.drop('Concrete compressive strength', axis=1) y_test = test_set['Concrete compressive strength'] |
ここはなんぞやと申しますと、訓練用データとモデル評価用データを、説明変数データと目的変数データに分けます。
やりたいことのイメージは下の図の通り。
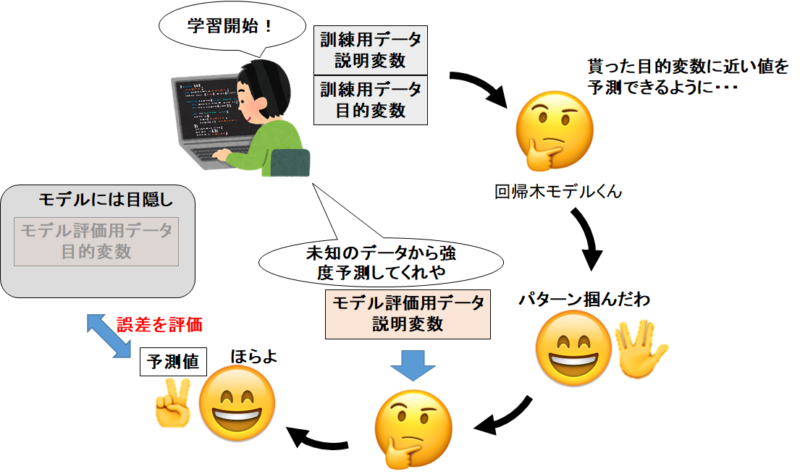
「訓練データでモデルを構築→モデル評価用データで予測値を出してもらう→モデル評価用データの正答値との誤差を評価」です。
よって、説明変数データ(訓練用データ)・目的変数データ(訓練用データ)・説明変数データ(モデル評価用データ)・目的変数データ(モデル評価用データ)に分けています。
回帰木のモデル構築
では回帰木のモデルを作っていきましょう。
1 2 | #回帰木モデルのインスタンス(空の箱みたいなモノ)を作る。回帰木の最大の深さは3。 clf = tree.DecisionTreeRegressor(max_depth=3) |
まずはインスタンスを作ります。clfは回帰木の計算するぞ!って宣言みたいなものです。
今回は試しに深さ3の回帰木にしましょう。
1 | model = clf.fit(X_train, y_train) |
ここで、訓練用データの説明変数と目的変数を渡して学習して貰います。
目的変数に沿う予測値を出せるように、必死になってパターンを見つけてくれているわけです。
予測値の出力
では構築したモデルに、モデル評価用データの説明変数を与えましょう。
1 | predicted = model.predict(X_test) |
「predicted」には、モデル評価用データの説明変数から導き出された予測値が収納されています。
1 | print(predicted) |

ほらね。
モデルを評価する
では、予測値と正答値がどの程度合っているか、可視化してみましょう。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #関数の処理で必要なライブラリ from sklearn.metrics import mean_squared_error from sklearn.metrics import r2_score #予測値と正解値を描写する関数 def True_Pred_map(pred_df): RMSLE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) R2 = r2_score(pred_df['true'], pred_df['pred']) plt.figure(figsize=(8,8)) ax = plt.subplot(111) ax.scatter('true', 'pred', data=pred_df) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') plt.text(0.1, 0.9, 'RMSLE = {}'.format(str(round(RMSLE, 5))), transform=ax.transAxes, fontsize=15) plt.text(0.1, 0.8, 'R^2 = {}'.format(str(round(R2, 5))), transform=ax.transAxes, fontsize=15) |
まずはおまじない。可視化できる関数です。とっつきづらいコードなので時間があるときに勉強してください。
1 2 | pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] |
可視化できる関数に突っ込めるように、予測値と正答値を加工します。
Pandasデータフレームの形に直しております。
1 | pred_df.head() |
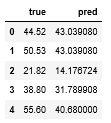
中身はこんな感じね。1列目が正答値で2列目が予測値です。
1 | True_Pred_map(pred_df) |
待ちに待った可視化!さてどうなる!!!!?!???!?
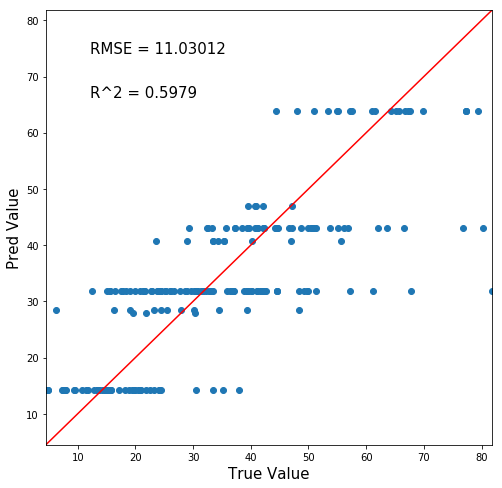
はいポンコツ。
ちなみに横軸が正答値、縦軸が予測値です。赤線に沿うようにプロットされるほど「正確に予測ができている」と言うことです。
まぁ深さ3の回帰木ですからね。しゃーなし。
左上の値は予測正確性を表す数値で、RMSEは小さくなるほど、R^2は大きくなるほど正確な予測となっています。
回帰木の深さを変えてみる。
回帰木の深さ3は浅すぎ説…?では深さを変えてみましょう。
まずは深さ4で。
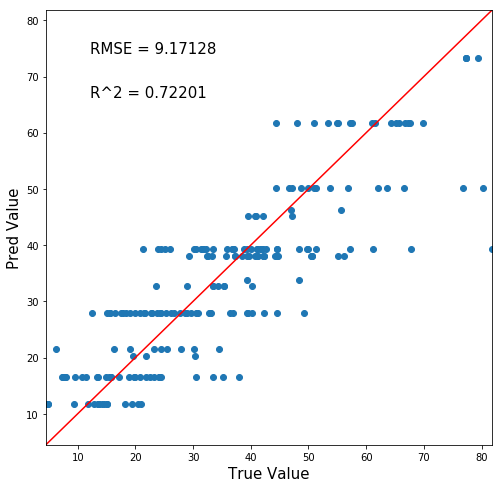
うーん。ましになったような。RMSE・R^2値も改善を示しています。
ちまちま深さを変えていたらきりがない。一気に評価しましょう。
1 2 3 4 5 6 7 8 9 10 11 | R2_list = [] count = [] for i in range(1, 100): clf = tree.DecisionTreeRegressor(max_depth=i) model = clf.fit(X_train, y_train) predicted = model.predict(X_test) pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] R2 = r2_score(pred_df['true'], pred_df['pred']) R2_list.append(R2) count.append(i) |
これは、回帰木の深さを1~99まで変化させて、それぞれのR^2値を記録するコードです。
R2_listに値が格納されていきます。
1 2 3 4 5 | plt.plot(count, R2_list, marker="o") plt.title("R^2 Values") plt.xlabel("max_depth of Tree") plt.ylabel("R^2 Value") plt.grid(True) |
ほんで可視化してみましょう。
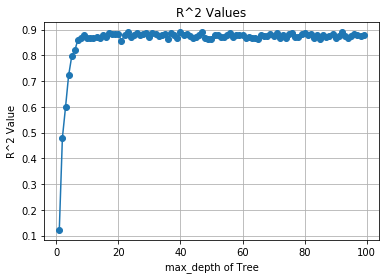
ほーう。大体深さ10くらいで頭打ちになるようですね。
Max深さ99回帰木の予測正答値マッピングをみてみましょう。
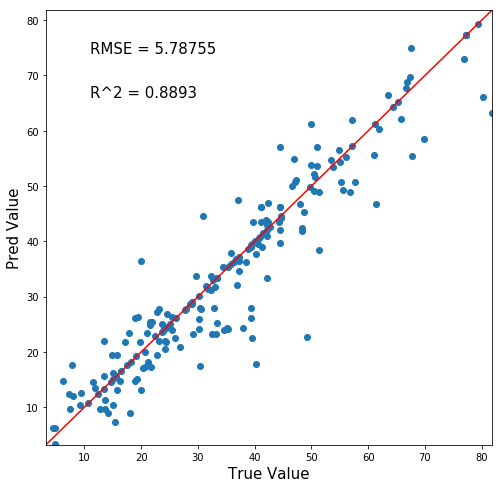
お!悪くないぞ!
正答値と予測値がマッチするy=xの赤線に沿っている!!
まとめ
ということで、今回は決定木(回帰木)で予測を行い、R^2=0.8893という値を出すことができました。
次の記事では別の機械学習手法である、ランダムフォレストで予測を行っていきましょう!
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
そして世界に革命を起こすこと間違いなしの機械学習全自動化ライブラリ「PyCaret」の使用方法や、今後の社会を予想した
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
も同時発売中です。
「PyCaret」を使いこなせば、22種類もの機械学習手法と一気に比較したり、ブラックボックスであるモデル内部の解析までわずか10数行のコードで行うことができます!
中身はこんな感じ↓
- Pythonのインストール
- Anaconda「JupyterNotebook」の起動
- 仮想環境構築
- データセット
- 中身の確認
- PyCaretを実装する
- ライブラリのインポート
- データ型を推測させる
- モデルの構築
- モデルの選択
- ハイパーパラメータチューニング
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- 機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
Python初心者でもインストール~全自動ライブラリ実装・解析まで出来るようになります。
980円:11080文字の教科書になっています。
全自動でもいいからパッと機械学習を実装したい!
「PyCaret」のような最新技術を使いこなしたいな。
という方には非常にオススメです。是非一読あれ!
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座

次の記事↓

↓ 効率的なPython学習はオンラインスクールがオススメ ↓
コメント