
どうも、リンです。
前回はLightGBMで回帰を行いました。
結果はこんな感じ。
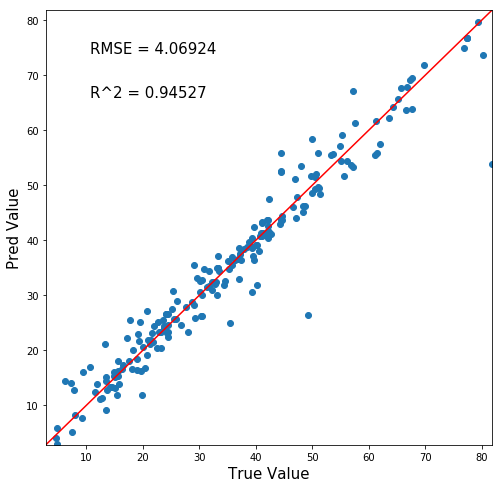
横軸が正答値、縦軸が予測値なので、y=xの赤線にプロットが沿うほど精度の良いモデルです。
かなり精度の良いモデルができたのではないでしょうか?
前回の記事↓

さて、前回の記事の問題点は「ハイパーパラメータをテキトーに決めた」という点でした。
ハイパーパラメータとは、機械学習モデルの挙動を変える「人間が手を付けるべきパラメータ」のことです。
今回の記事では、ハイパーパラメータを最適な数値にチューニングをしてモデルの精度を高めましょう!
ハイパーパラメータチューニングって何をやるの?
さて、ハイパーパラメータをチューニングすると言っても具体的に何をやればいいのでしょうか?
これは、世界最大の機械学習競技サイト「Kaggle」のトップランカーの間でも度々話題になります。
一昔前は、「手作業で最適なパラメータを探す」が主流だったのですが、最近は「自動化」が流行っています。
手作業だと疲れますし、ある意味職人技になってその人個人だけの技術になってしまいます。
そこで登場したのが「ハイパーパラメータ自動化ライブラリ」です。
ハイパーパラメータ自動化ライブラリはいくつか存在しますが、最近流行りだしたモノが「Optuna」というライブラリですね。
この「Optuna」を使って、筆者も普段からハイパーパラメータチューニングを行っています。
「Optuna」とは?
オープンソースのハイパーパラメータ自動最適化フレームワークOptuna™は、ハイパーパラメータの値に関する試行錯誤を自動化し、優れた性能を発揮するハイパーパラメータの値を自動的に発見します。オープンソースの深層学習フレームワークChainerをはじめ、様々な機械学習ソフトウェアと一緒に使用することが可能です。
Preferred Networks, Inc. Optuna公式サイトより引用
つまり「ハイパーパラメータチューニング専用の自動化ライブラリだよ」ということですね。
Optunaのウリは次の3点です。
- 検索空間と目的関数を別に記述することで可読性・管理性の向上
- 見込みのないパラメータを早期で枝切りするアルゴリズム
- 並列処理化・チューニング過程を保存することで中断再開が可能
まぁかなり便利な機能が揃っていますね。
これで性能もいいんだから、使われるにきまってますよ。
肝心の「パラメータ探索のアルゴリズム」はおそらくベイズ最適化という統計学的アプローチで最適解を見つけ出す手法の応用だと考えられます。(詳細は見ていない)
ベイズ最適化自体はそこまで難しい手法ではないので、変なバグとかは流石になさそう。
実際にコードを書いて実践してみる
では早速Optunaを使ってハイパーパラメータチューニングをしてみましょう
ライブラリのインポート
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #データ解析用ライブラリ import pandas as pd import numpy as np #データ可視化ライブラリ import matplotlib.pyplot as plt import seaborn as sns #LightGBMライブラリ import lightgbm as lgb #訓練データとモデル評価用データに分けるライブラリ from sklearn.model_selection import train_test_split #ハイパーパラメータチューニング自動化ライブラリ import optuna #関数の処理で必要なライブラリ from sklearn.metrics import mean_squared_error from sklearn.metrics import r2_score |
今回はOptunaを加えます。コマンドプロンプトで「pip install optuna」及び、Anacondaを使用の方はアナコンダプロンプトで「conda install optuna」を稼働させてインストールしておいてくださいね。
追記:Anacondaを使用の方は、「conda install optuna」ではインストールできないとの声を頂きました。optunaは「conda install -c conda-forge optuna」とアナコンダプロンプトで実行してインストールしてください。下調べが徹底出来ておらず申し訳ございませんでした。
CSVファイルの取り込み
1 | concrete_data = pd.read_csv(r'C:\Users\concrete.csv', engine='python') |
例によって、コンクリートデータが入っているパスを入れてくださいね。
コンクリートデータを持っていない方は↓の記事からダウンロードしてください。
出来れば今までの記事を見ておくことをオススメします。

訓練用データとモデル評価用データに分割
1 | train_set, test_set = train_test_split(concrete_data, test_size=0.2, random_state=4) |
ここで、コンクリートデータを「訓練用」と「モデル評価用」に分けます。今回も8:2でいきましょう。
1 2 | print(len(train_set)) print(len(test_set)) |
訓練用データは824セット。モデル評価用データは206セットと表示されます。8:2ですね。
説明変数と目的変数に分割
1 2 3 4 5 6 7 | #訓練データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_train = train_set.drop('Concrete compressive strength', axis=1) y_train = train_set['Concrete compressive strength'] #モデル評価用データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_test = test_set.drop('Concrete compressive strength', axis=1) y_test = test_set['Concrete compressive strength'] |
前回の記事通り。
説明変数と目的変数を「LightGBM用のデータセット」に加工します。
1 2 | lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test) |
こうすることで高速化できるんでしたよね。
目的関数の設定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | def objective(trial): params = {'metric': {'rmse'}, 'max_depth' : trial.suggest_int('max_depth', 1, 10), 'subsumple' : trial.suggest_uniform('subsumple', 0.0, 1.0), 'subsample_freq' : trial.suggest_int('subsample_freq', 0, 1), 'leaning_rate' : trial.suggest_loguniform('leaning_rate', 1e-5, 1), 'feature_fraction' : trial.suggest_uniform('feature_fraction', 0.0, 1.0), 'lambda_l1' : trial.suggest_uniform('lambda_l1' , 0.0, 1.0), 'lambda_l2' : trial.suggest_uniform('lambda_l2' , 0.0, 1.0)} gbm = lgb.train(params, lgb_train, valid_sets=(lgb_train, lgb_eval), num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50) predicted = gbm.predict(X_test) RMSE = np.sqrt(mean_squared_error(y_test, predicted)) pruning_callback = optuna.integration.LightGBMPruningCallback(trial, 'rmse') return RMSE |
なんとも分かりにくいコードが出てきましたね。これはOptunaにぶち込む情報をまとめた関数みたいなものです。
たとえば’max_depth’ : trial.suggest_int(‘max_depth’, 1, 10)というコードは、「’max_depth’というパラメータにおいて、1~10の整数値で探索してくれ」という指示です。
trial.suggest_uniformは浮動小数点数で探せ。0.0~1.0なら0.5421456852って値も探せます。
trial.suggest_loguniformは対数浮動小数点です。
ハイパーパラメータの探索範囲を指定したら、
1 2 3 4 5 6 7 8 9 | #上記コードの一部を説明!実行はしないでね gbm = lgb.train(params, lgb_train, valid_sets=(lgb_train, lgb_eval), num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50) predicted = gbm.predict(X_test) RMSE = np.sqrt(mean_squared_error(y_test, predicted)) |
この部分でLightGBMのモデル構築→予測→正答値予測値誤差の計算 を行っています。
ここは前回の記事通りですね。
1 2 | #上記コードの一部を説明!実行はしないでね pruning_callback = optuna.integration.LightGBMPruningCallback(trial, 'rmse') |
このコードはOptuna特有で、「rmse値で評価して、見込みのないパラメータは早期に枝刈りするよ」という指令です。
1 2 | #上記コードの一部を説明!実行はしないでね return RMSE |
はこの関数のまとめみたいなモノで、returnで出した値を最小にするようにOptunaはチューニングをしていきます。
Optunaの起動
1 2 | study = optuna.create_study() study.optimize(objective, timeout=3600) |
この2行で実行できます。
studyというOptuna学習過程~結果を格納する箱を作ります。
study.optimize(objective, timeout=3600)という部分でその箱に対して実行を掛けます。
先ほど作った目的関数の「objective」には、「探索すべきパラメータとその範囲・LightGBMモデルの構築~RMSE値の導出・早期枝刈りの指令・最小化すべき値(今回はRMSE値)」が入っていましたよね。
timeout=3600とは、「パラメータチューニングは3600秒ひたすら計算して一番ベストな結果を出力します。」という意味です。つまり1時間後に計算が終わるってこと。
実行すると、なんだかとても頑張って探索している感のある出力をしてきますね。放置しましょう。
結果の出力
1 2 3 4 5 6 | print('Best trial:') trial = study.best_trial print('Value:{}'.format(trial.value)) print('Params:') for key, value in trial.params.items(): print('"{}" : {}'.format(key, value)) |
このコードを実行すると、1時間の探索で最もスコアが良かった(RMSE値が小さくなった)パラメータの数値を出力します。
私の場合は以下のような数値でした。
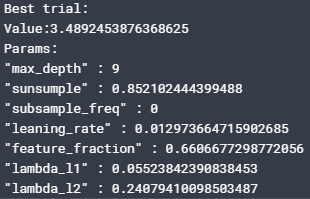
ほんじゃあこれをLightGBMに導入して、結果を見てみましょうか。
前回の記事通りだから、一気にいきますよ。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | #予測値と正解値を描写する関数 def True_Pred_map(pred_df): RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) R2 = r2_score(pred_df['true'], pred_df['pred']) plt.figure(figsize=(8,8)) ax = plt.subplot(111) ax.scatter('true', 'pred', data=pred_df) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') plt.text(0.1, 0.9, 'RMSE = {}'.format(str(round(RMSE, 5))), transform=ax.transAxes, fontsize=15) plt.text(0.1, 0.8, 'R^2 = {}'.format(str(round(R2, 5))), transform=ax.transAxes, fontsize=15) #Optunaで最適化されたパラメータ params = {"metric": {'rmse'}, "max_depth" : 9, "subsumple" : 0.852102444399488, "subsample_freq" : 0, "leaning_rate" : 0.012973664715902685, "feature_fraction" : 0.6606677298772056, "lambda_l1" : 0.05523842390838453, "lambda_l2" : 0.24079410098503487 } #LightGBMのモデル構築 gbm = lgb.train(params, lgb_train, valid_sets=(lgb_train, lgb_eval), num_boost_round=10000, early_stopping_rounds=100, verbose_eval=50) #モデル評価用データで予測値出力 predicted = gbm.predict(X_test) #可視化関数にぶち込めるように予測値と正答値をデータフレームに加工 pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] #可視化関数を実行 True_Pred_map(pred_df) |
さあ結果はどうなる!
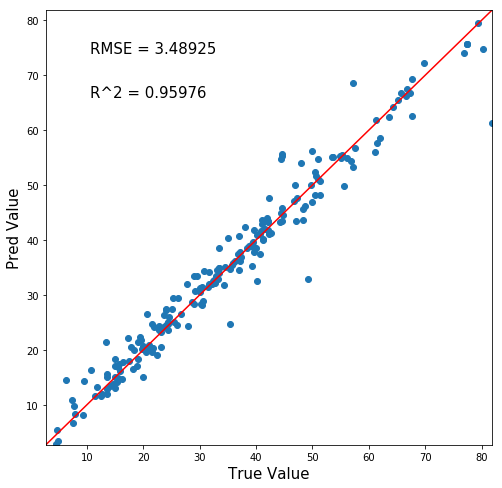
おおお!さらに精度が上がりましたね!!
チューニング前はRMSE=4.06924, R^2値=0.94527でした。
というわけで、ハイパーパラメータチューニングをすることでモデルの精度を上げることができましたね!
まとめ
ハイパーパラメータを変えると、モデルの精度を上げることができます。
しかし、ハイパーパラメータチューニングは「最後にやるべき手法」だと私は考えています。
なぜなら「より予測に効く特徴量作り」に時間を割いた方が精度の良いモデルを作れるからです。
いずれ「特徴量作り」の記事も書きますので、是非見てくださいね~
では!
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
そして世界に革命を起こすこと間違いなしの機械学習全自動化ライブラリ「PyCaret」の使用方法や、今後の社会を予想した
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
も同時発売中です。
「PyCaret」を使いこなせば、22種類もの機械学習手法と一気に比較したり、ブラックボックスであるモデル内部の解析までわずか10数行のコードで行うことができます!
中身はこんな感じ↓
- Pythonのインストール
- Anaconda「JupyterNotebook」の起動
- 仮想環境構築
- データセット
- 中身の確認
- PyCaretを実装する
- ライブラリのインポート
- データ型を推測させる
- モデルの構築
- モデルの選択
- ハイパーパラメータチューニング
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- 機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
Python初心者でもインストール~全自動ライブラリ実装・解析まで出来るようになります。
980円:11080文字の教科書になっています。
全自動でもいいからパッと機械学習を実装したい!
「PyCaret」のような最新技術を使いこなしたいな。
という方には非常にオススメです。是非一読あれ!
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座

【参考書籍】
テーブルデータでの機械学習手法が綺麗にまとめられています。
機械学習競技サイト「Kaggle」のトッププレイヤー達が共同著者です。とってもオススメ。
次の記事↓


コメント