
どうも、リンです。
前回は決定木(回帰木)を使ってコンクリートの圧縮強度を予測しました。
結局、回帰木の最大深さを99にして下の図のような結果となりましたね。
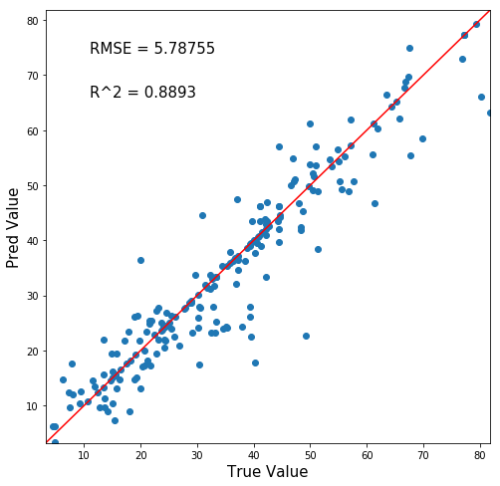
横軸が正答値、縦軸が予測値ですので、y=xの赤線にプロットが沿うほど正確な予測ができるモデルと言うわけです。
↓前回までの記事




今回は前回の回帰木を応用した機械学習モデル「ランダムフォレスト」を使って予測をしていきましょう!
ランダムフォレストとは?
さて、ランダムフォレストとは一体なんぞや?ざっくり、要所を絞って説明していきます。
回帰木
まず前回の回帰木を思い出しましょう。
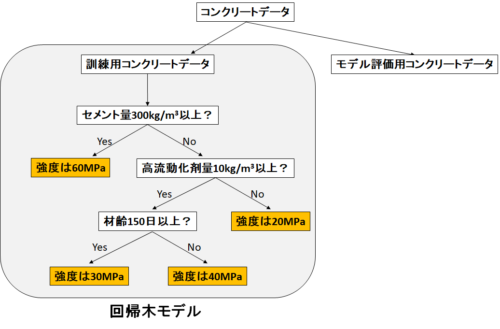
回帰木とは、「データを最もよく分割する”Yes or No”の質問」を繰り返すことで、目的変数(コンクリート強度)を予測するというモデルでした。
回帰木を複数作る
さて、こんな木が1つだけで正確に予測できるのでしょうか?
ランダムフォレストの原点はここです!(開発者の気持ちは知らん)
いくつもの回帰木を作ってやって、多数決とか平均とかで予測をしようぜって発想がランダムフォレストです。
訓練データ全部使って、闇雲に3個の回帰木を作ったとしましょう。
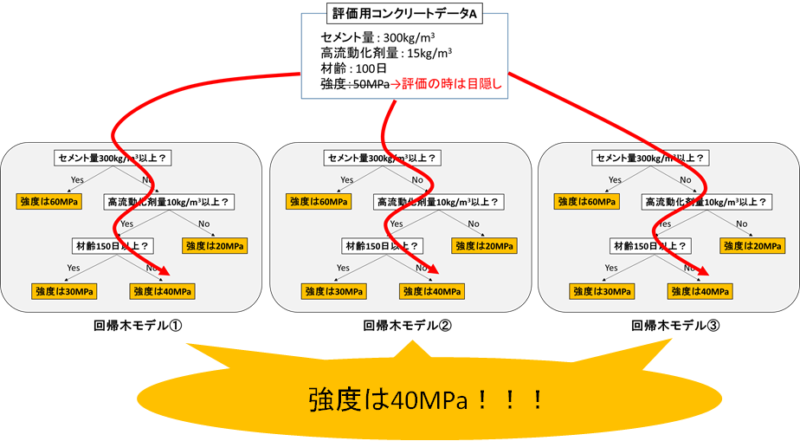
全く計算から、全く同じモデルが3つでき、全く同じ答えが3つ返って来るだけです。
図にするとアホらしくて可愛いけど、これはよくない。
ランダムフォレストの”ランダム”とは?
じゃあ、回帰木一つ一つが違うモデルになればいいですよね。性格が違う子を3人用意すればいいわけです。
そこで2つの工夫を凝らします。
- 訓練データを違うものにする
- 「Yes or Noの質問」を作る条件を変える
の2つです。
訓練データを違うものにする
これは非常に分かりやすいですね。与えるデータの種類を違うものにすれば回帰木の挙動も変わりそうですよね。
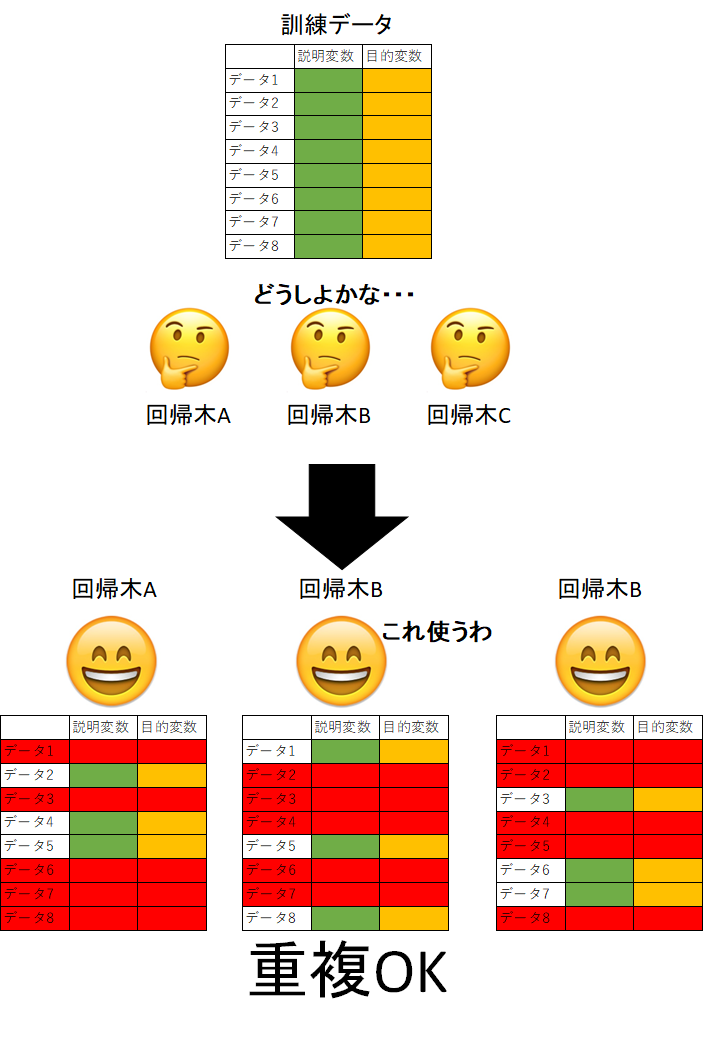
ちなみに重複は許します。データ全体というより、一部が変わっていれば「若干性格の違う回帰木」が期待できますからね。
「Yes or Noの質問」を作る条件を変える
こちらは少しわかりづらいですね。超分かりやすく解説します。
まず、訓練用データから最初の「Yes or Noの質問」を考えます。(回帰木がね)
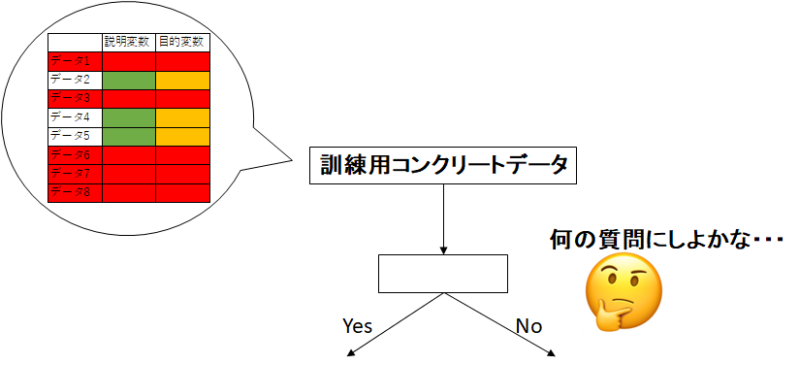
この質問作りにランダム性を持たせます。
数ある説明変数から、「使用できる説明変数を限定」します。
デフォルトでは、説明変数の種類の平方根の数だけ使用させるようにするのです。

しゃーなしで作られた「Yes or Noの質問」で木は分岐していきます。
続いて、またランダムに限定された説明変数から、「よく分割できる質問」を作っていきます。
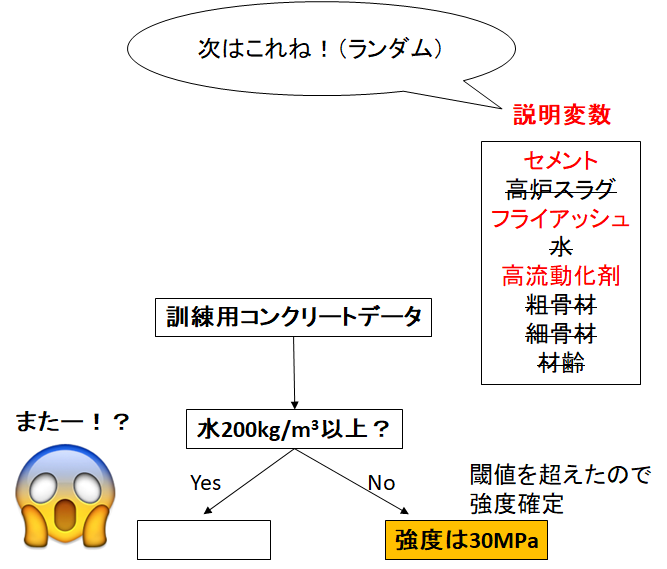
全ての枝が閾値を超えて、強度を確定するまで続けます。
これで一つの回帰木が完成です!
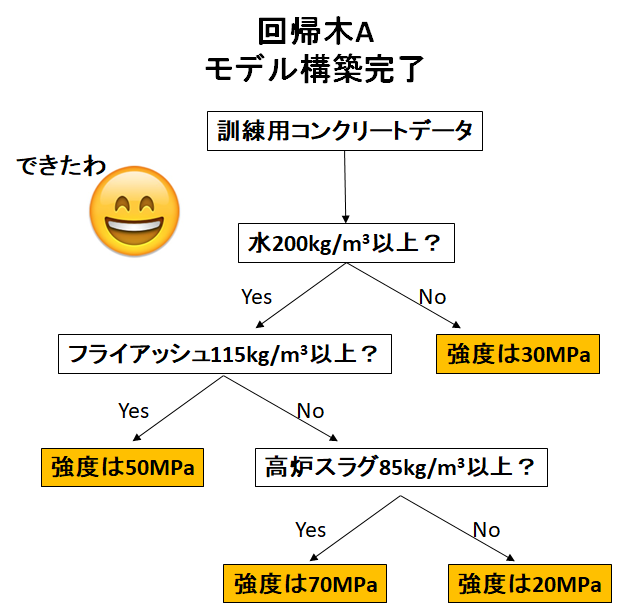
これならば、回帰木毎にかなりのランダム性が生まれますね!
「若干性格の違う回帰木を作る」という目標は達成できました!
結果を集約する
こうして生まれた「性格の違う回帰木」は、同じモデル評価用データを与えても違う答えを出してきます。
それぞれの予測値から、「代表値」を選び最終的な予測値として出力します。
代表値とは、平均や中央値などですね。
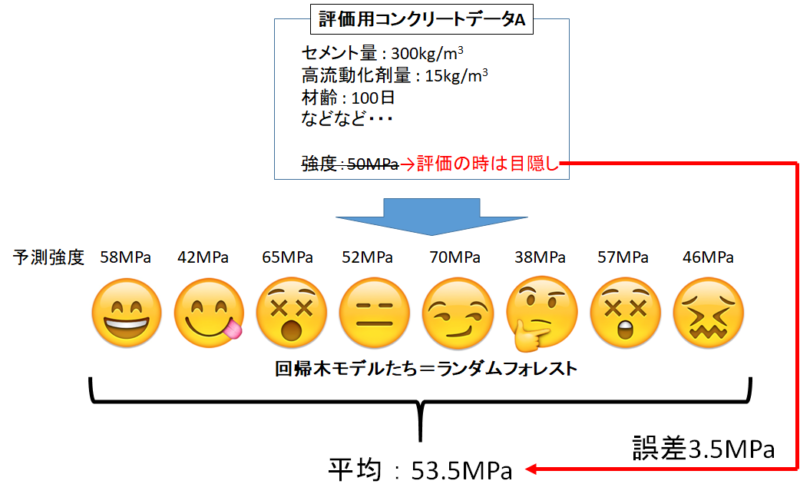
このように、一つ一つの回帰木はポンコツでも、数が集まれば中々精度の良い予測値を返すことができます!
以上がランダムフォレストの概要になります。
「数式が無ければ満足できん!」というワガママ秀才さんはググってください(手抜き)
実際にモデルを作って評価する
さっさとコードを見せろやと?おせっかちさんですね。
ほんじゃあ、最初からいきましょう。
ライブラリのインポート
1 2 3 4 5 6 7 8 9 10 11 12 13 | #データ解析用ライブラリ import pandas as pd import numpy as np #データ可視化ライブラリ import matplotlib.pyplot as plt import seaborn as sns #ランダムフォレストライブラリ from sklearn.ensemble import RandomForestRegressor #訓練データとモデル評価用データに分けるライブラリ from sklearn.model_selection import train_test_split |
今回はランダムフォレスト用のライブラリを入れますよ。
簡単にランダムフォレストが作れる優れもの!
CSVファイルの取り込み
1 | concrete_data = pd.read_csv(r'C:\Users\concrete.csv', engine='python') |
例によって、コンクリートデータが入っているパスを入れてくださいね。
コンクリートデータを持っていない方は↓の記事からダウンロードしてください。
出来れば今までの記事を見ておくことをオススメします。
訓練用データとモデル評価用データに分割
1 | train_set, test_set = train_test_split(concrete_data, test_size=0.2, random_state=4) |
ここで、コンクリートデータを「訓練用」と「モデル評価用」に分けます。今回も8:2でいきましょう。
1 2 | print(len(train_set)) print(len(test_set)) |
訓練用データは824セット。モデル評価用データは206セットと表示されます。8:2ですね。
説明変数と目的変数に分割
1 2 3 4 5 6 7 | #訓練データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_train = train_set.drop('Concrete compressive strength', axis=1) y_train = train_set['Concrete compressive strength'] #モデル評価用データを説明変数データ(X_train)と目的変数データ(y_train)に分割 X_test = test_set.drop('Concrete compressive strength', axis=1) y_test = test_set['Concrete compressive strength'] |
前回の記事通り。イメージは下の感じですね。今回は回帰木モデルくんじゃなくて回帰木モデルくん”たち”ですけどね!書き直すのがめんどくさい!(手抜き)
ランダムフォレストのモデル構築
ほんじゃあランダムフォレストのモデルを作っていきましょう。
といっても、ほとんど前回と同じようなコードで書けます。便利な世の中ですね。
1 2 | #ランダムフォレストのインスタンス(空の箱みたいなモノ)を作る。回帰木の数は100。 RFclf = RandomForestRegressor(n_estimators=100) |
まずはインスタンスを作ります。RFclfはランダムフォレスト作るぞ!って宣言(箱)みたいなものです。
回帰木モデルくんたちは100人集まって予測してもらいます。がんばってね。
1 | model = clf.fit(X_train, y_train) |
では100人の回帰木モデルくんたちに訓練用のデータを渡します。
内部では、先ほど解説したように「ランダムのデータ」「ランダムの説明変数」で回帰木が作られていきます。
1 | predicted = model.predict(X_test) |
そしてパターンを掴んだ100人の回帰木モデルくんにモデル評価用データ(目的変数である強度は目隠し)を与えて、予測値を出してもらいます。
predictedには予測値の”代表値”が格納されています。
1 | print(predicted) |
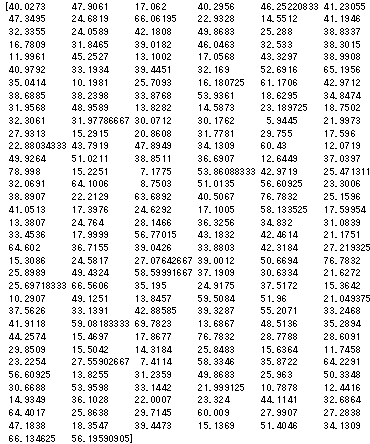
モデル評価用データは206セットあったので、206個の予測値が格納されています。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #関数の処理で必要なライブラリ from sklearn.metrics import mean_squared_error from sklearn.metrics import r2_score #予測値と正解値を描写する関数 def True_Pred_map(pred_df): RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) R2 = r2_score(pred_df['true'], pred_df['pred']) plt.figure(figsize=(8,8)) ax = plt.subplot(111) ax.scatter('true', 'pred', data=pred_df) ax.set_xlabel('True Value', fontsize=15) ax.set_ylabel('Pred Value', fontsize=15) ax.set_xlim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) ax.set_ylim(pred_df.min().min()-0.1 , pred_df.max().max()+0.1) x = np.linspace(pred_df.min().min()-0.1, pred_df.max().max()+0.1, 2) y = x ax.plot(x,y,'r-') plt.text(0.1, 0.9, 'RMSE = {}'.format(str(round(RMSE, 5))), transform=ax.transAxes, fontsize=15) plt.text(0.1, 0.8, 'R^2 = {}'.format(str(round(R2, 5))), transform=ax.transAxes, fontsize=15) |
正答値と予測値を可視化するおまじない。前回と同じ関数ですよ。
1 2 | pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] |
可視化関数にぶち込めるように正答値(y_test)と予測値(predicted)を合体させています。
合体後がpred_dfってやつ。
1 | pred_df.head() |
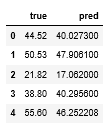
1列目が正答値(y_test)で2列目が予測値(predicted)です。
さぁ!いよいよ可視化です!ランダムフォレストは正確な予測ができるのか!?!??!?
1 | True_Pred_map(pred_df) |
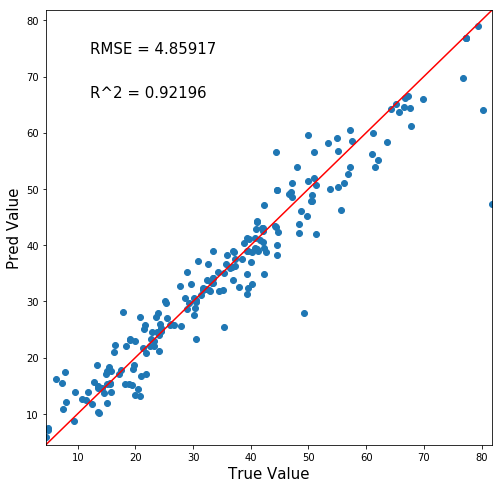
おっ!ええやん!!!
y=xの赤線に割と沿っている。つまり正確な予測ができているということですね。
今回の記事はここまで・・・とはいかないよなぁ?
回帰木100本・・・少なくない?
回帰木100本がどのくらい素晴らしいのか、分からないですよね。
そこでランダムフォレストの回帰木1本~1000本でRMSE値がどのように変化するのか見てみましょう。
ちなみにRMSE値は0に近づくほどGoodです。
1 2 3 4 5 6 7 8 9 10 11 | RMSE_list = [] count = [] for i in range(1, 1001): RFclf = RandomForestRegressor(n_estimators=i) model = RFclf.fit(X_train, y_train) predicted = model.predict(X_test) pred_df = pd.concat([y_test.reset_index(drop=True), pd.Series(predicted)], axis=1) pred_df.columns = ['true', 'pred'] RMSE = np.sqrt(mean_squared_error(pred_df['true'], pred_df['pred'])) RMSE_list.append(RMSE) count.append(i) |
回帰木の数を1本ずつ増やして、正答値(y_test)と予測値(predicted)から算出されるRMSE値をRMSE_listに格納していきます。
ちなみに割と計算に時間がかかります。(30分くらい)プログラミング始めて最初の頃って、こういう「待ってる時間」がなんか「強いプログラマー」って感じで嬉しかった記憶があります。
あまりに暇ならお風呂行くかコーヒー飲むか別の記事見るかしててくださいね。
記事執筆と並行でコード回してるから筆者も暇なうです。
・・・計算終わりましたかね?
では可視化のコードを書きましょう。
1 2 3 4 5 6 | plt.figure(figsize=(16,8)) plt.plot(count, RMSE_list, marker="o") plt.title("RMSE Values", fontsize=30) plt.xlabel("n_estimators", fontsize=20) plt.ylabel("RMSE Value", fontsize=20) plt.grid(True) |
お待たせしました。ランダムフォレストで回帰木の数を変動させると予測性能はどうなるのか!?!?!
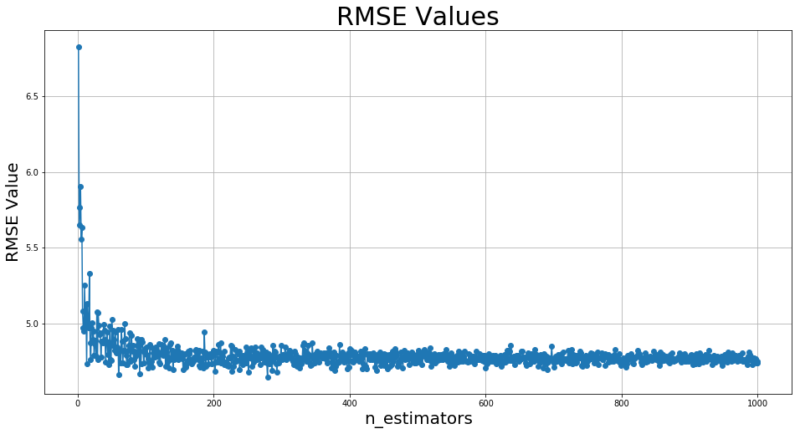
ほーーう。回帰木の数は100程度で頭打ちらしいですね!まぁ400本くらいで許してやりましょうか!
回帰木400本の正答値予測値マッピングはこちら。
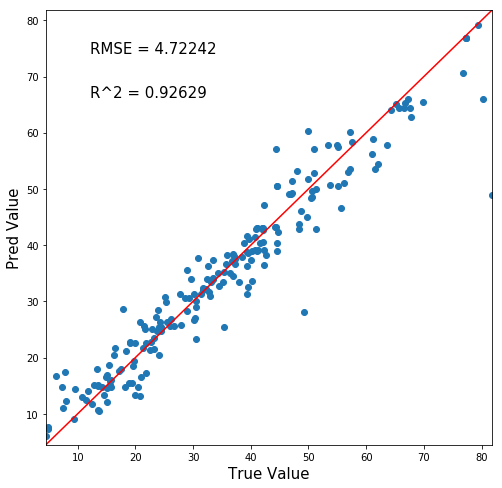
・・・あんまり変わらないですね。
特徴量重要度を出そう
「予測できました!」で終わりじゃちょっと寂しい。
ランダムフォレストにはとっても嬉しい機能があります。それが「特徴量重要度」。
分かりやすく言うと「特徴量(説明変数)の、予測に役立った度数」です。(分かりづらい)
求め方はこんな感じ。
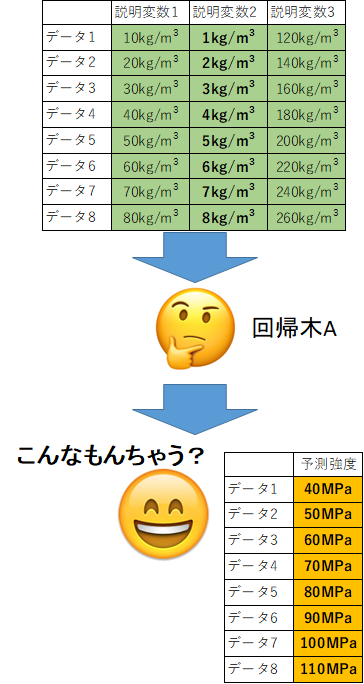
まずは作った回帰木にデータを渡し、予測強度を出してもらいます。
次に、同じデータで「ある説明変数をごちゃまぜにして」渡します。
予測強度に大きな変化が現れたら「予測に重要な説明変数」。そうでなかったら「予測に重要でない説明変数」ってことです。
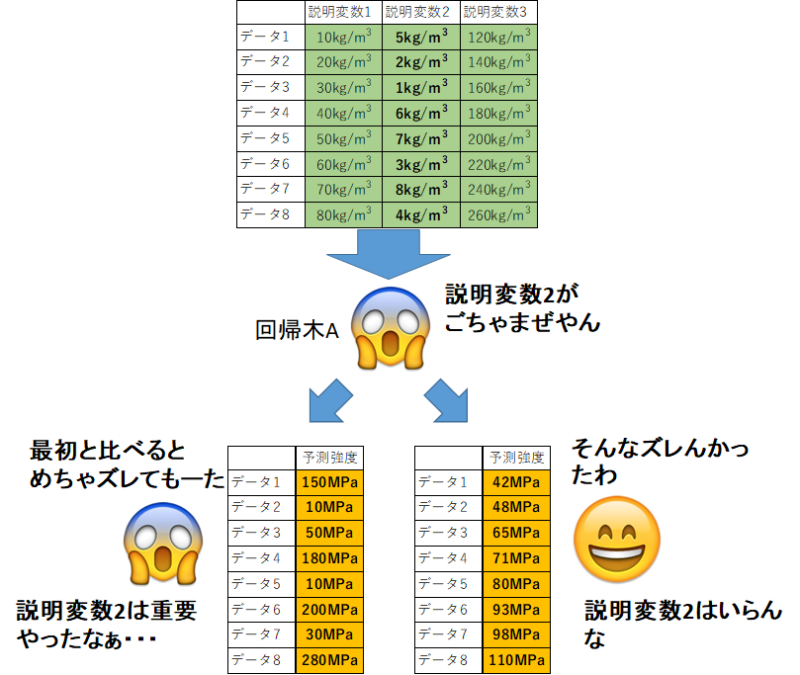
コードはすぐ書けますが、内部ではこのようなことがおきて重要度を算出しています。
それでは実践でコードを書いていきましょう!
おそらく皆さんは、先ほどの回帰木1000本のランダムフォレストモデルが残っていますからそれをそのまま使っていきましょう。
1 2 3 | feature_importances = pd.DataFrame([X_train.columns, model.feature_importances_]).T feature_importances.columns = ['features', 'importances'] feature_importances |
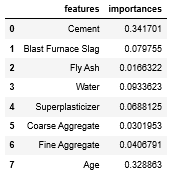
みにくいコードでごめんなさい。ちゃんと重要度が表示されていますね。
特徴量の名前は訓練用データ(X_train)の列名(columns)から持ってきました。
それに対応する重要度は、回帰木1000本のランダムフォレストモデル(model)をfeature_importances_のメソッドを掛けると出力してくれます。
その後の.Tは転置の操作で、横並びのデータフレームになったから縦並びにしたかっただけ。
さて、こんな数値のデータフレームじゃあぼくちゃんは満足できません。可視化せねば。
1 2 3 4 | plt.figure(figsize=(20,10)) plt.title('Importances') plt.rcParams['font.size']=10 sns.barplot(y=feature_importances['features'], x=feature_importances['importances'], palette='viridis') |
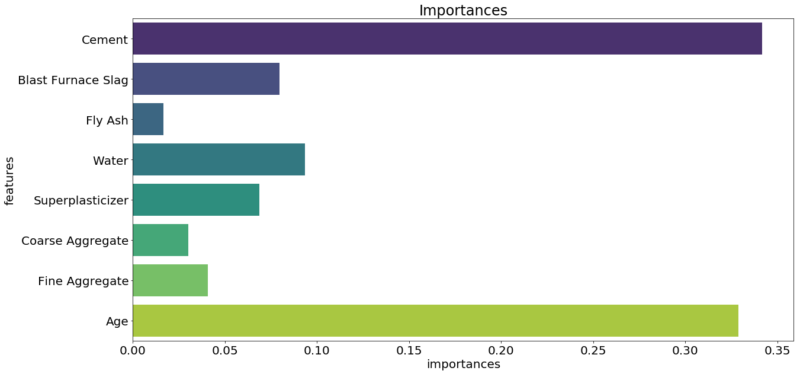
美しい・・・やっぱこれだよなぁ・・・
ライブラリSeaborn、略してsns こういう綺麗なグラフを描けるので素晴らしい。
さて、どうやらセメント量と材齢が重要な特徴量らしいですね。
1 | sns.pairplot(concrete_data, x_vars=['Cement', 'Age'], y_vars=['Concrete compressive strength']) |
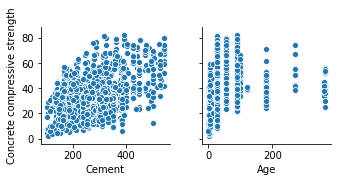
まぁわからなくもない。けどランダムフォレストは何を考えているのかわからない。
真髄はランダムフォレストの溝知るってことですね。
まとめ
ってことで、今回はランダムフォレストの簡単な原理を紹介&実装をしていきました。
1つの回帰木よりはかなり正確なモデルを作ることができましたね!
実はランダムフォレストには設定すべきパラメータがいくつかあります。今回はデフォルト値でしたけどね。
それらをいじくったときにどうなるかをまた紹介していきます!(気が向いたら)
では!
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
そして世界に革命を起こすこと間違いなしの機械学習全自動化ライブラリ「PyCaret」の使用方法や、今後の社会を予想した
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
も同時発売中です。
「PyCaret」を使いこなせば、22種類もの機械学習手法と一気に比較したり、ブラックボックスであるモデル内部の解析までわずか10数行のコードで行うことができます!
中身はこんな感じ↓
- Pythonのインストール
- Anaconda「JupyterNotebook」の起動
- 仮想環境構築
- データセット
- 中身の確認
- PyCaretを実装する
- ライブラリのインポート
- データ型を推測させる
- モデルの構築
- モデルの選択
- ハイパーパラメータチューニング
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- 機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
Python初心者でもインストール~全自動ライブラリ実装・解析まで出来るようになります。
980円:11080文字の教科書になっています。
全自動でもいいからパッと機械学習を実装したい!
「PyCaret」のような最新技術を使いこなしたいな。
という方には非常にオススメです。是非一読あれ!
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座

次の記事↓

↓ 効率的なPython学習はオンラインスクールがオススメ ↓
コメント