
さて、前回はデータセットの配布と中身の確認をしていきました。
↓前回の記事

配布したデータはローカルのどこかに保存しておいてくださいね。
今回は「探索的データ解析(EDA)」を行っていきましょう。
探索的データ解析(EDA)とは?
探索的データ解析(Explanatory Data Analysis : EDA)とはデータの構造・分布・相関などを分析してより深い理解を得るという解析手法になります。
分かりやすく言うと、手あたり次第にデータを分析して中身を理解しようぜってフェーズです。
機械学習ってのは、データの中身がある程度理解できていないとモデルの改良が進みません。
それどころかデータの本質を理解していないがために、気づかずに全く役に立たないモデルを作り出してしまうことさえあります。
探索的データ解析(EDA)で使う道具箱の紹介
Pythonで探索的データ解析(EDA)を行う場合、使う道具は大体3つです。
EDAってよりは、もはやPython3種の神器って感じですね。とっても便利。
Pythonをインストールして間もない方は、これらのライブラリがお使いのパソコンにインストールされていない可能性があります。
コマンドプロンプトを開き、「pip install pandas」「pip install numpy」「pip install matplotlib」と順に打ち込むことでインストールできます。
もしもPythonの開発環境としてAnacondaとお使いの方は標準でインストールされております。
実際に探索的データ解析をしていこう
ではやっていきましょう。
ライブラリのインポート
まずは各ライブラリのインポートから。
1 2 3 4 5 6 7 | #データ解析用ライブラリ import pandas as pd import numpy as np #データ可視化ライブラリ import matplotlib.pyplot as plt import seaborn as sns |
ちょっとまって、seabornって一体なんぞや?
これはmatplotlibの派生ライブラリで、かっちょええグラフを作ってくれるライブラリです。
インストールされていない方はコマンドプロンプトで「pip install seaborn」でどうぞ。
データセット取り込み
はい。次に配布したデータセットを取り込んでいきます。
1 | concrete_data = pd.read_csv(r'C:\Users\Desktop\concrete.csv', engine='python') |
pdって付いているから、データセットをPandasで読み込んでいるってことですね。
「C:\Users\Desktop\concrete.csv」ってところにはあなたがデータを保存しているパスを入れてくださいね。
データの表示
読み込んだデータがどのような中身なのか確認しましょう。
1 | concrete_data.head() |

わお。ちゃんと読み込まれてる。
head()ってのは「最初の5行を表示するよ」って命令になります。
逆に「最後の5行を表示するよ」は?
1 | concrete_data.tail() |

tail() しっぽ。 分かりやすいようで分かりにくいような。
要約統計量の表示
1 | concrete_data.describe() |
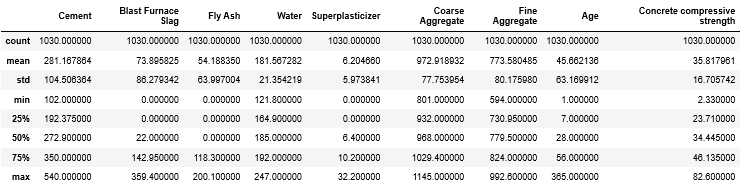
ふーむ。何書いてあるか分からん。ということで意味はこんな感じ。
| 項目名 | 意味 |
|---|---|
| count | データの個数 |
| mean | 平均 |
| std | 標準偏差 |
| min | 最小値 |
| 25% | 第一四分位数 |
| 50% | 第二四分位数 |
| 75% | 第三四分位数 |
| max | 最大値 |
中学の数学を学んだ方なら分かるかな?気になるならググってください(サボり)
欠損値の確認
与えられたデータをそのまま使うのは非常に危険です。
データセットってのもいくつかのミスがありまして、空白の値があるかも知れません。
そんな欠損値があるか調べてみましょう。
1 | concrete_data.isnull().sum() |
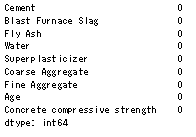
いやいや、なんと見事なデータセット。欠損値はゼロです。
…そんなのつまらんじゃん。
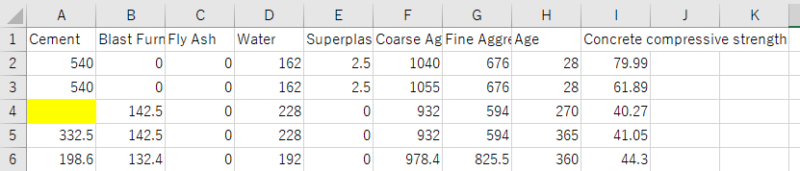
欠損値を作ってやりましたよ。
もう一度concrete_dataを読み込んで調べてみましょう。

おぉ~~。しっかり欠損値をカウントできていますね。Pandasってすごい。
まぁここまでで参考になるようなデータはイマイチ手に入りませんね。強いて言うなら「綺麗なデータ」ってことが分かったくらいです。
データは「可視化」してなんぼですからね。次は「可視化」するEDAを行っていきましょう。
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
そして世界に革命を起こすこと間違いなしの機械学習全自動化ライブラリ「PyCaret」の使用方法や、今後の社会を予想した
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
も同時発売中です。
「PyCaret」を使いこなせば、22種類もの機械学習手法と一気に比較したり、ブラックボックスであるモデル内部の解析までわずか10数行のコードで行うことができます!
中身はこんな感じ↓
- Pythonのインストール
- Anaconda「JupyterNotebook」の起動
- 仮想環境構築
- データセット
- 中身の確認
- PyCaretを実装する
- ライブラリのインポート
- データ型を推測させる
- モデルの構築
- モデルの選択
- ハイパーパラメータチューニング
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- 機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
Python初心者でもインストール~全自動ライブラリ実装・解析まで出来るようになります。
980円:11080文字の教科書になっています。
全自動でもいいからパッと機械学習を実装したい!
「PyCaret」のような最新技術を使いこなしたいな。
という方には非常にオススメです。是非一読あれ!
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座

↓次の記事

↓ 効率的なPython学習はオンラインスクールがオススメ ↓
コメント