
どうもリンです。AIベンチャー出向中で修行しています。
さて、最近巷を賑わせている「PyCaret」というライブラリが登場したということで早速使っていきましょう。
「PyCaret」とは簡単に言うと「機械学習自動化ライブラリ」です。
単純に自動化というならば、skcit-learnだって面倒な数式モデルを自動化してくれていました。
今回の「PyCaret」のスゴイ所は
- データ型の推測
- データ前処理
- 複数モデルの比較
- パラメータチューニング
- データ構造可視化
- モデル学習結果可視化
- アンサンブルやスタッキング自動化
などなど、機械学習で割と面倒くさい所を一気にそして高速にやってくれるということでコード量を圧倒的に減らすことができます。
機械学習界隈に革命を起こすこと間違いなしのライブラリなので、早速実装しましょう。
最後に「PyCaret」などの機械学習自動化ライブラリの登場で「機械学習エンジニアの未来はどうなるのか?」について考察していきます。
データセット
今回使うデータセットは、当ブログおなじみの「コンクリートデータ」でございます。
「コンクリート材料の配合データとコンクリート強度」が載ったテーブルデータです。
使用しやすいようにxlsx形式に変換しておきました。ダウンロードしてローカルに落としておいてください。
「Concrete Compressive Strength Data Set」 ←発行元
【著作権】I-Cheng Yeh, “Modeling of strength of high performance concrete using artificial neural networks,” Cement and Concrete Research, Vol. 28, No. 12, pp. 1797-1808 (1998).
中身の確認
これはカルフォルニア大学アーバイン校が公開しているオープンデータであり、1030データ入っております。
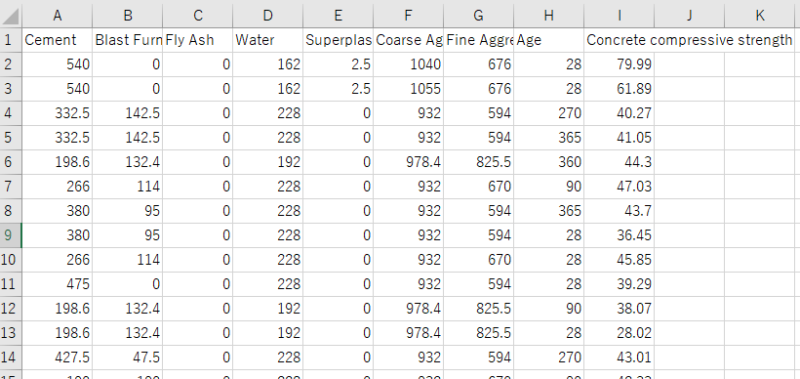
↑中身はこんな感じ。
| 説明変数 | cement : セメント(kg/㎥) Blast Furnance Slag : 高炉スラグ(kg/㎥) Fly Ash : フライアッシュ(kg/㎥) Water : 水(kg/㎥) Superplasticizer : 高流動化剤(kg/㎥) Coarse Aggregate : 粗骨材(kg/㎥) Fine Aggregate : 細骨材(kg/㎥) Age : 材齢(1〜365日) |
| 目的変数 | Concrete compressive strength : コンクリート圧縮強度(MPa) |
となっております。
材料データから、コンクリートの圧縮強度を予測しましょうってモチベーションですね。
カテゴリ変数が入っていないので簡明ですし、マテリアルズインフォマティクスに近いものを感じてなんだか楽しそうなので、当ブログのモデルデータとなっております。
PyCaretを実装する
PyCaretのインストール
Anacondaを使用している方はAnaconda promptで「pip install pycaret」でインストールします。それ以外の方はコマンドプロンプトで。
現在はPython3.6系でしかインストールできませんでした。3.7はムリ。
Anacondaの仮想環境でPython3.6系を選びましょう。仮想環境について分からない方は記事の後半をご覧ください。
ライブラリのインポート
必要なライブラリだけインポートします。
1 2 3 4 | import pandas as pd from pycaret.regression import * concrete_data = pd.read_excel(r'C:\Users\\concrete.xlsx') |
今回はpandasとpycaretの回帰(regresson)クラスのみインポートします。
データ型を推測させる
ではPyCaretを起動します。
1 | exp1 = setup(concrete_data, target = 'Concrete compressive strength', ignore_features = None) |
第一引数:データフレーム
第二引数:目的変数の列名
第三引数:無視する列名(今回は無し)
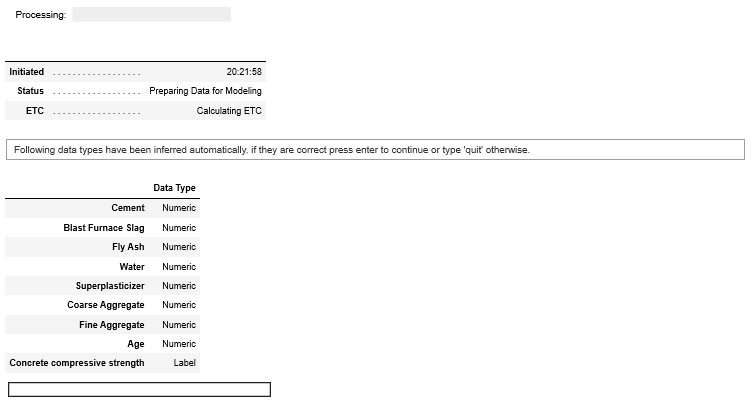
このようなコマンド画面が出てきます。
注目すべきは「Data Type」私の場合はConcrete compressive strength(目的変数)はLabelで、それ以外はNumeric(数値)となっています。
Concrete compressive strength(コンクリート強度)も一応数値なのですが、pycaretのLabelというデータ型の概念が分からん…
ちなみに明らかに間違っていたら、元のデータを書き換えるしかないようです。
数値データなのにカテゴリー変数と認識されたら、有効数字増やして数値にする的なね。
私の場合は問題ないので、エンターを押せば進みます。

するとこんな感じにセットアップが終了して、データフレームの要約を出してくれます。
モデルの構築
では早速機械学習モデルの構築をしていきましょう。
1 | compare_models() |
たったこれだけ。すげえ。
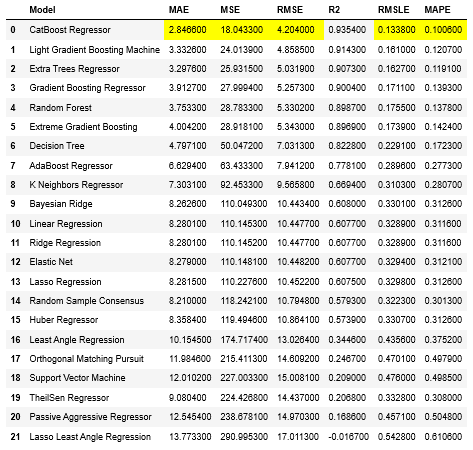
このように21種の回帰モデルを作成し、精度の高い順にランキングを付けてくれます。
今回は「Catboost」「LightGBM」「ExtraTrees」が上位3種類ですね。全て決定木系アルゴリズムですが、ridgeやベイジアンモデルなども中位以降にあります。
この評価は、デフォルトでは交差検証10回の平均で算出しています。訓練データ:評価データ=7:3で分割しているようですね。交差検証の回数は指定できますが、シャッフルの有無は選択できません。
↓交差検証についてはこの記事で解説しています。

ちなみにこの時点ではハイパーパラメータチューニングはされていません。
「どのモデルが適合するか」の指標として使えますね。
モデルの選択
残したいモデルをモデルオブジェクトとして作ります。
1 | lightgbm = create_model('lightgbm') |
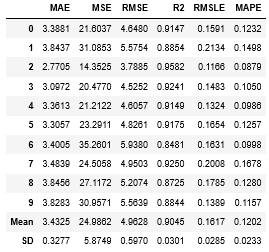
lightgbm変数にモデルオブジェクトが格納され、ついでに10回交差検証の結果が出力されます。
交差検証によっては結果がバラツキますね。
ハイパーパラメータチューニング
今のままではデフォルトのパラメータなので、チューニングしましょう。
1 | tuned_lightgbm = tune_model('lightgbm', n_iter = 500, optimize = 'r2') |
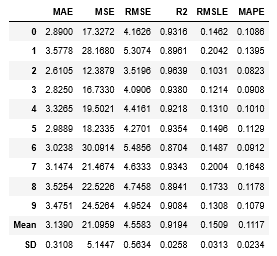
スコアが上がりましたね!ハイパーパラメータチューニングの成果です!
n_iterはランダムグリッドサーチ(ハイパーパラメータの取りうる値をランダムにして、一番精度が高かったパラメータを採用する方法)の回数を指定します。今回は500回探索します。
ここが少し残念なポイント。ベイズ最適化やoptunaのステップワイズ法が存在する中で、ランダムグリッドサーチは物足りない気がしますね。
optimizeは評価方法ですね。
学習結果の可視化
申し訳ありませんが、ここから先は有料記事となります。
【この先の内容】
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- AIエンジニアが予測する機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
- 補足
- Pythonインストール方法
- Python仮想環境構築方法
について
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
980円:11805文字の記事となっています。
原理について詳しく知りたい方は↓の教科書もオススメです。
機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
コメント
pythonインストール機械学習實相まで完全理解講座 pycaret完全理解講座を
購入したいのですが 購入方法を教えてください お願いします
ありがとうございます!
記事にリンクは貼ってあったのですが分かりづらかったですかね…
↓↓↓こちらにURLを貼っておきます!
pycaret完全理解講座→<https://brain-market.com/u/rin-effort/a/bYTOykzMgoTZsNWa0JXY>
機械学習理解講座→<https://brain-market.com/u/rin-effort/a/bEjMwYjMgoTZsNWa0JXY>
返信ありがとうございます クロムーブレインーログインー支払いがクレジットカード(なし)しか出来ないのですがーーー 貴講座ソフト購入ののため ツイッターにはいつたしだいです よろしくお願いいたします。f7222227@yahoo.co.jp
返信ありがとうございます。
おそらくクレジットカードを所持していないので購入ができないという意図でよろしいでしょうか?
現在のBrain(販売元プラットフォーム)はクレジットカード決済しか受け付けていないようです…
同じような有料記事販売プラットフォームであるnoteも同様ですね。。
よろしければ記載のメール上で別途購入方法と、記事の受け渡しについて相談させて頂ければと存じます。