
どうも、リンです。超大手自動車メーカーに勤めており、現在はAIベンチャーに出向して修行をしております。
最近は機械学習を学びたいという人が増えていますね。
僕も数年前に学び始めたので、当時の記憶は真新しいです。
機械学習勉強するぞー!!!
と一念発起したのは良いものの、皆ぶち当たる壁は同じです。
で、何から勉強すればいいのさ?Pythonって言語?入門書から買ってみようかな?
はい。
- 何から勉強していいか分からん
- Pythonの勉強の最果てに機械学習があるイメージ
- 機械学習を使いこなせる未来が見えない
- 数学とか無理やん
- 機械学習理論書?見たけど呪文やん。
ここらで躓きますよね。というか心が折れます。
そこで私がガチ初心者用に、わかーりやすい教科書を作ってやりましたよ!
今回は機械学習の勉強でよくある勘違いと現状を語り、私が執筆した教科書がどう役立つのか?何が一般的な教本と違うのか?解説をしていきたいと思います!
Python初心者用が読むべき機械学習本
まずは宣伝。
機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
ってことで現状の機械学習習得の問題点を解説していきます!
初心者が機械学習を習得するまで【一般論】
Pythonの勉強を始めて、機械学習が構築できるようになるまでってどんなイメージですかね?
- 基礎文法の勉強
- 応用文法の勉強
- 拡張機能の勉強
- 数学の勉強
- 統計学の勉強
- 機械学習の理論勉強
- 機械学習の実装
こんな感じじゃないですかね?私はこんなイメージを持ってました。
Pythonの教科書や、ネットでの情報って「上記の手順に沿いましょう!」みたいな事言ってくるんですよね。
ゴチャゴチャ言わずに早く実装させてくれ!!
ってめっちゃ思ってました。
で、そのあと壁にぶち当たるんですよね。
機械学習の実装方法てPython玄人向けの教材しかないやん!!
数式だらけやし!こんなん理解できないやん!
ってなるんですわ。
- 教材の内容が分からない
- 分からない部分の解説書を探す
- 解説書も分からない
「は?」ってなりますわ。なんでいっつも玄人向けなん?
- 「はじめてのパターン認識」って本買う←分かりやすそう
- 内容クッソ難しい(鬼数式の羅列)
「は???」ってなりますわ。絶対”はじめて”って言ったらあかん。
学会発表でポンコツわいの発表に対して、研究分野の第一人者が「素人質問で恐縮ですが~」からボコしに来る”アレ”と同じ匂い。
これが機械学習界隈の現状なんですわ。
みんなも困ってますよね。
初心者は最短で実装まで漕ぎ着くことが重要
私含めて、みーんな勘違いしてたんですよ。
- 基礎文法の勉強
- 応用文法の勉強
- 拡張機能の勉強
- 数学の勉強
- 統計学の勉強
- 機械学習の理論勉強
- 機械学習の実装
↑こんな遠回りな勉強方法しなくてOK。
正解はこうです。
- 最小限の基礎文法の勉強
- 機械学習の実装
- 作りたいもの見つけて、必要な文法・知識を勉強
こう言うといくつか疑問点が湧きますよね。
機械学習なんてメチャ難しそうじゃん。初めから実装なんて無理だよ・・・
→余裕で出来ます。実装は超簡単です。
理論を勉強していない状態で機械学習を使ってはいけない!
→難しい数式なんて後でOK。それより「内部で何が起きているかのイメージ」が重要です。イメージに数式は必要ありません。こう言う老害エンジニアこそイメージが追い付いておらず無能です。
機械学習を実装するのに難解なPython構文は覚えなくていい
正直、機械学習の実装に難しい文法は必要ないんです。
本当に基礎的な部分でOK。
Pythonの全文法中0.2%の文法で機械学習の実装できます!!(個人の感想です)
それにも関わらずそこらの書籍は何なのか?
基礎的な文法を勉強しましょう!(150ページ)
あ、この技術も必要だよ!(必要なし)
では機械学習の理論を勉強しましょう!(クソムズ数式)
じゃあ実装しましょう!(コードの詳しい解説なし)
( ゚Д゚)「・・・」
分からなかったら次の本買ってね!
( #゚Д゚)「教える気ねーじゃん!」
最初に難解な理論から学ぶのはおかしい。
真面目な人ほど理論から勉強したがるんですよね。(私です)
例えば、やったことないけどテニスを上達したいと思っていますと。
- テニスの教科書を買う
- テニスの練習をする
どっちを先にやったほうがいいですか?後者ですね(即答)
テニスとはどんな感覚でやるものなのかを理解してからのほうが教科書の内容も身に付きますよね。
私の経験談
機械学習も同様です(分かりづらい)
私も同じ失敗をしてました。。。
最初は機械学習の本とかpythonの入門書とか読んでたんです。
でも何にも頭に入っていかない。
だからまずは機械学習の大会に出てみたんです。行動力命。
するとめちゃめちゃ上達が早い。吸収が早い。応用が利くようになる!
まず根幹の「機械学習の実装」が出来たからなんですよね。
英語で例えよう
例えばあなたが「英語堪能になりたい!」と思っているとしましょう。中学の教科書から学びなおすのが最速ですか?
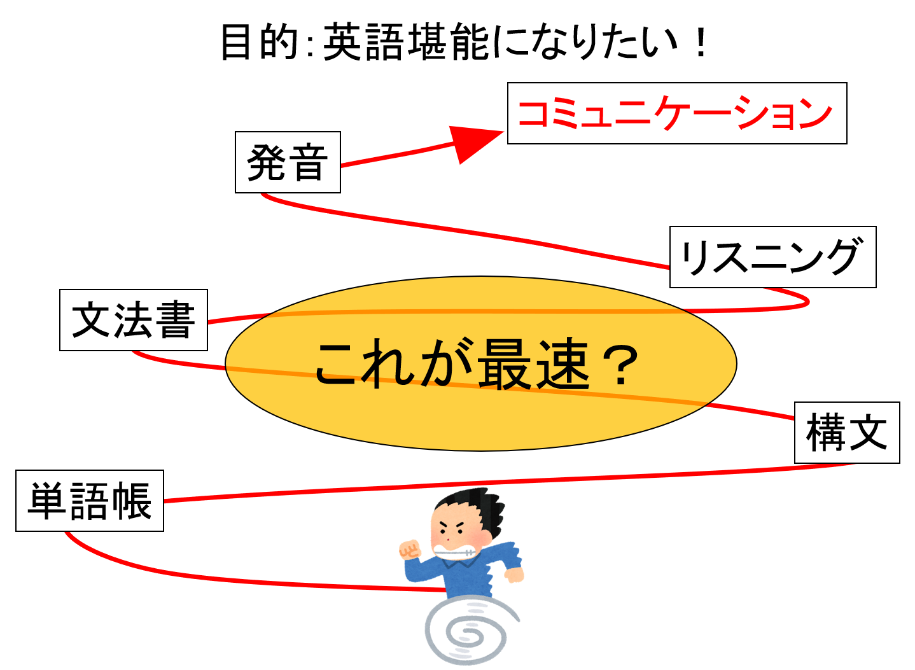
違いますよね?今すぐアメリカで2年暮らすのが最速で英語を学ぶ方法ですよね?

継ぎ接ぎな英語でも、とりあえずコミュニケーションがほんの少し取れるようになってからスラングでも正確な構文でも学べばいいじゃないですか!!
機械学習も同じです。Python入門書?無料サイト?なぜ遠回りするんですか?
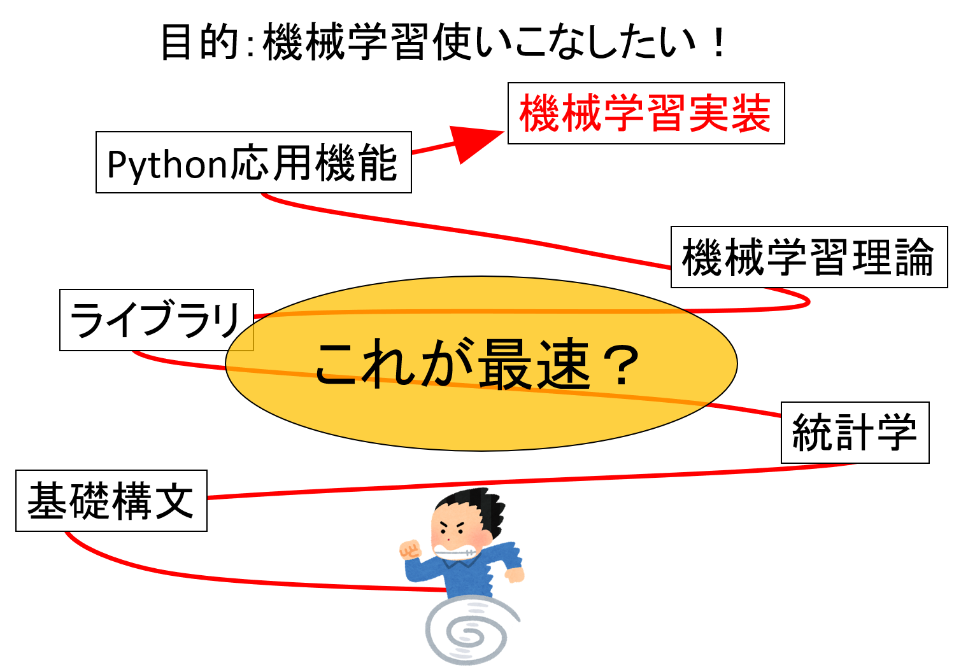
間違っています。まずは最小限の知識だけ付けたら「実装してしまう」。

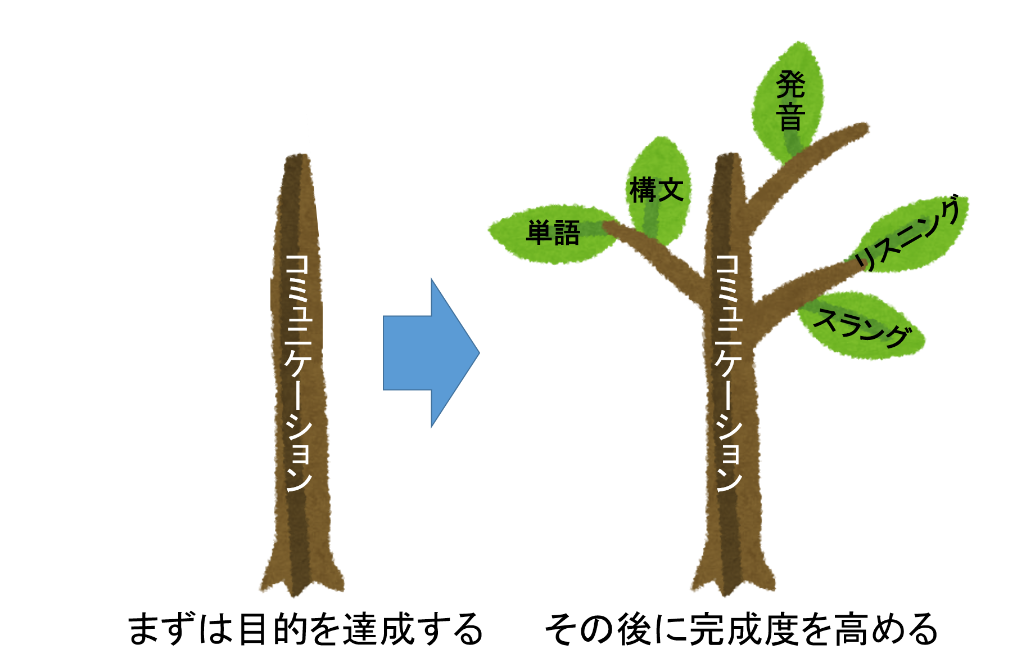
それから理論だったり応用技術を学ぶ。これが最速です。
「機械学習の実装」「機械学習を使いこなす」という目的を達成してから、周辺知識の完成度を高めていけばいいんです。
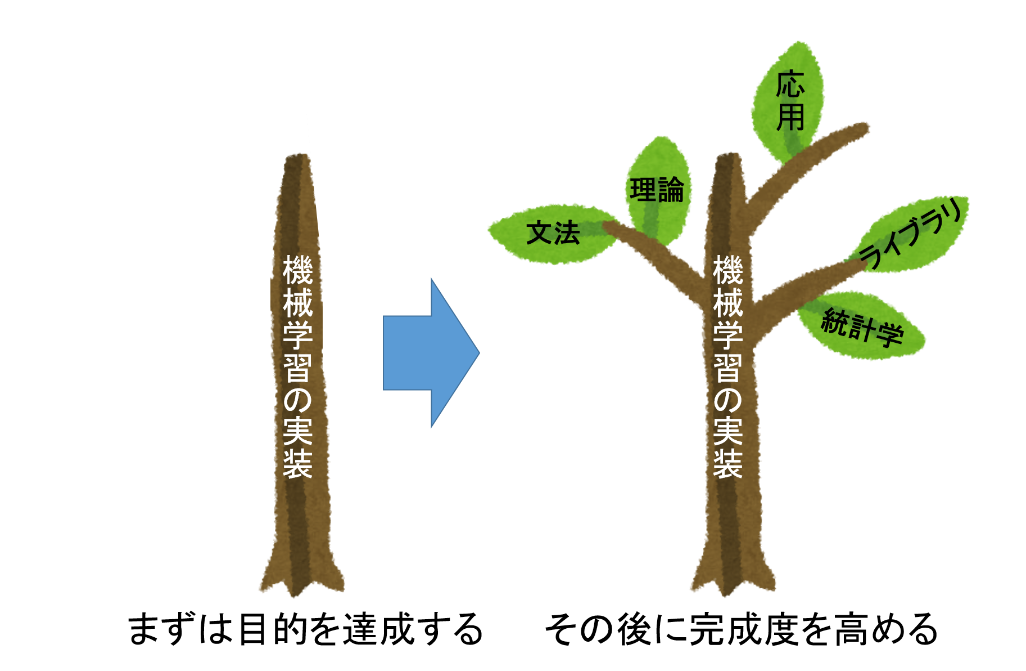
実装できたら理論が理解できる
実装ができると理論が理解できるんですよ。
実装というより、私の教材に載ってる「機械学習原理イメージ」ですかね。
くっそ!数式難しすぎて何言ってるかわからん!
から変化が起きます。
あん?あの部分のこと数式にしてんのか?分かりづらい数式使うなよな~。
まぁ言いたいことは分かるから理解できるわ。
と、イメージが先行するおかげで数式も理解が進むわけです。
というわけで初心者にオススメ教材です。
こんな失敗談があるし改善されない世の中ですので、私が解決策を作りました!
あー!回りくどい事しないで機械学習を最速で学ぶ教材がなんでないんや!
文法も原理も実装も、初心者の目線に立って解説してくれや!!
というお悩みを解決します。
- インストール方法から画像付きで解説します。
- ガチで最小の文法紹介しかしません。
- 機械学習原理を懇切丁寧に、イメージ画像付きで解説します。
- 最先端技術まで解説&実装します(大変すぎて死にそうだった)
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
コメント
初めまして。
「機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座」について質問があり、ご連絡させて頂きました。
下記の2つの質問について、ご回答頂けないでしょうか?
質問1 コードについて
ランダムフォレストを実行しようの項のIn [58]のコード中で、
model = reg.fit(X_train, y_train)
となっておりますが、
model = RFreg.fit(X_train, y_train)
ではないでしょうか?
質問2 モデルの使用方法について
ランダムフォレストやLightGBMで作成したモデルを発展させれば、concrete compressive strengthを最大化するようなパラメータを求めることも可能なのでしょうか?
可能な場合、その方法をご教示頂けないでしょうか?参考となる書籍やブログ等のご紹介でも結構です。
ご多用のところ恐縮ですが、ご回答くださいますと幸いです。
本書のおかげで、初心者の私でも無事に実装することができました。
本書で学んだことをベースに、さらに研鑽して業務にも応用したいと考えております。
よろしくお願いいたします。
ご指摘ありがとうございます!質問1に関してはtypoですね。。
model = RFreg.fit(X_train, y_train)に修正申請を出しました。数日以内に修正されるでしょう。
質問2について回答します。
「concrete compressive strengthを最大化するようなパラメータ」という意図が正確に把握できませんでしたので、考えられる方法について紹介します。
おそらく「concrete compressive strengthを最大化するような材料データの組み合わせを発見できるかどうか」という疑問だと解釈します。
回答としては、総当たり的に見つけるしかなく、「求めたい目的変数の値→それに一致する説明変数の組み合わせを一意に決定する」という手法は不可能です。
具体的な分析方法としては
①現在あるコンクリートデータを使用して機械学習モデルを構築する
②数万個のランダムに作成した材料データの組み合わせを総当たり的に機械学習モデルに予測させてconcrete compressive strengthを導出する
③その中でconcrete compressive strengthが最大になった材料データ組み合わせを採用する
という方法になります。
「ランダムに作成した材料データが実際にコンクリートとして成り立つかどうかは別途吟味するor最初から制約条件を設けてランダムなデータを作る」という工夫も必要です。
機械学習のモデルは説明変数→目的変数予測しか出来ません。
「求めたい目的変数の値→それに一致する説明変数の組み合わせ」が出来ると楽なんですがね。。
このような「データサイエンス×材料工学」という領域はマテリアルズインフォマティクスという技術になります。
私も数年研究していた時期がありましたが、モデルの工夫で何とかなる領域は狭く「どのようなデータセットを用意できるか」が重要です。
今回のコンクリートデータのような「材料データを大きく振ったランダム様のデータ&強度を予測するに十分な説明変数が備わったデータ」は模範的ですね。
https://rin-effort.com/2020/04/01/ml-careful/
↑こちらの記事にデータ収集に関する注意点なども載せております。
https://brain-market.com/u/rin-effort/a/bYTOykzMgoTZsNWa0JXY
↑モデル選択についてはPDCAを高速化できる自動化ライブラリも登場しています。実務で扱う分にはこのようなライブラリを用いてモデル選択やハイパーパラメータチューニングに割く時間を最小化できます。
「機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座」を読み込んだ後であれば、自動化ライブラリの内部挙動なども理解できるでしょう。
効率化した時間を用いて、「機械学習用データセットの収集」に充てた方が課題解決には建設的な行動かと思われます。
以上、回答として適切であれば幸いです。
意図していない回答であれば、またコメントをお願い致します。