
どうも、リンです。
ハッカーの皆さん、機械学習の技術の一つ「スタッキング」をご存じですか?
Kaggleに参加している方ならご存じかもしれないですね。
どっかで聞いたことあるような…
でも難しそうだから実装は出来そうにないや。
と思っている方が多いのではないでしょうか。
でも、この「スタッキング」の実装は割と簡単です。
この記事を見れば
実装する手順が見えた!今からコード書いてみよう!
となります。
今回はそのくらいの理解度を目指して「スタッキング」を解説していきます。
機械学習の「スタッキング」とは?
機械学習のスタッキングとは、「複数の機械学習モデルを積み重ねて精度を上げる手法」です。
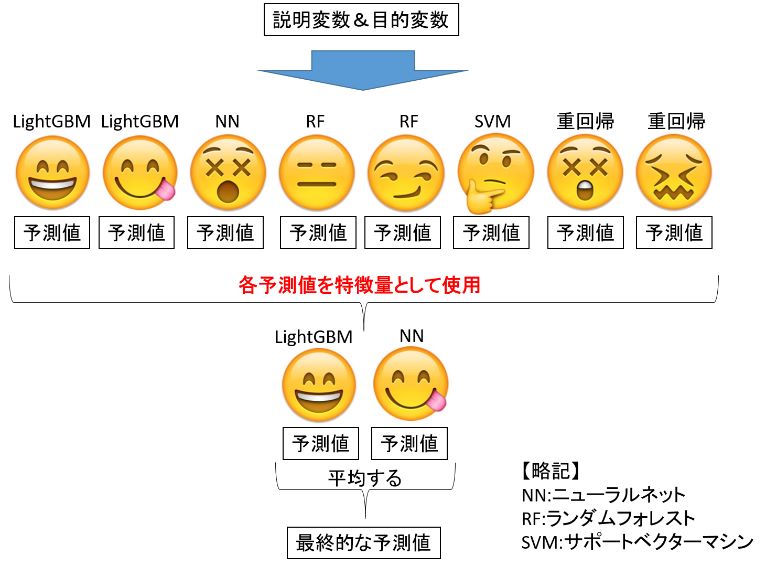
スタッキングの一例としては上画像のような感じです。あくまで一例です。
単一で予測タスクを完了できるような機械学習モデル(LightGBM~重回帰)の予測値を、特徴量として使おうというアイデアになります。
スタッキングを実装するための詳細
概要は何となく理解できたよ。
でも実装するには具体的にどうすればいいの?
ということで、より詳しく解説します。
データを訓練用と評価用に分ける
まず、データを「モデル訓練用データ」と「モデル評価用データ」に分けます。
「なんで分けるの?」って疑問を持つ方はこちらの記事に詳細を載せています。
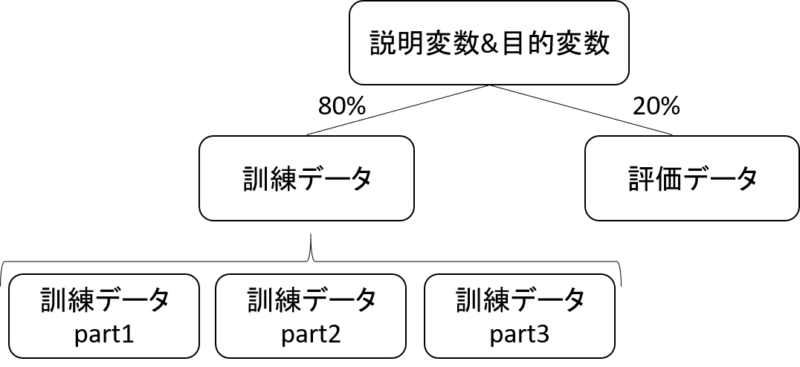
同時に、交差検証の為に訓練用データを3つに分割します。
今回は簡単のために3回交差検証にしますが、実際には3~5回くらいが一般的ですね。
交差検証が分からない方はこちらの記事でお勉強してください!
交差検証で訓練データ&評価データの予測値を出力する
では次に、モデル訓練→訓練データと評価データの予測値を出力しましょう。
3回交差検証なので、機械学習モデルは3つ作ります。
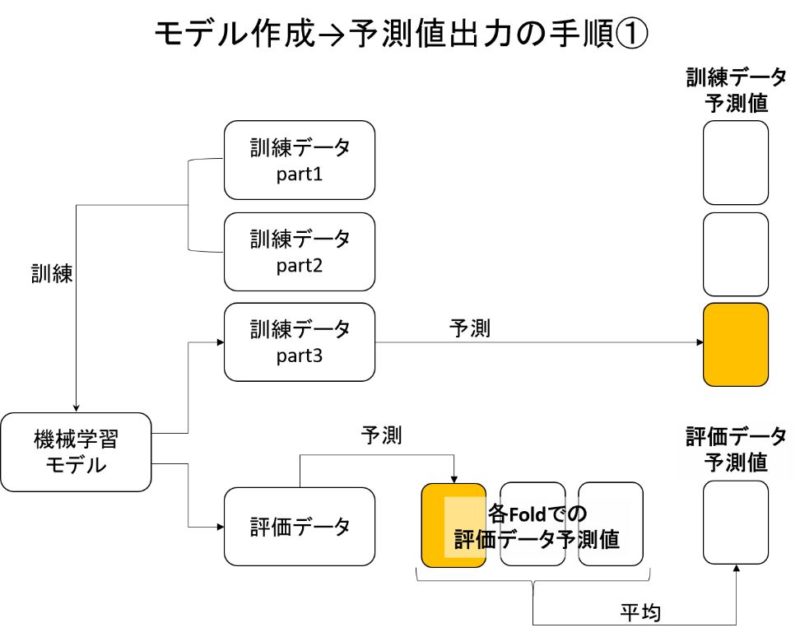
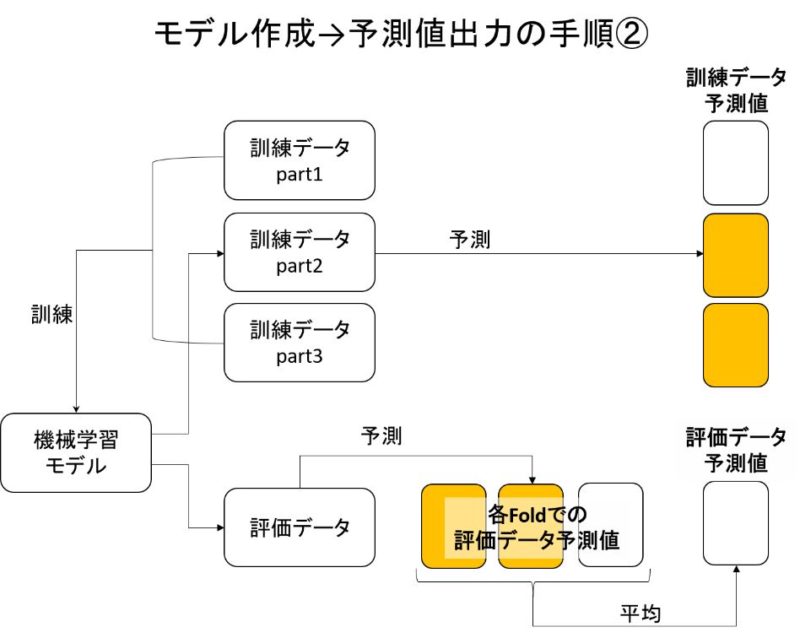
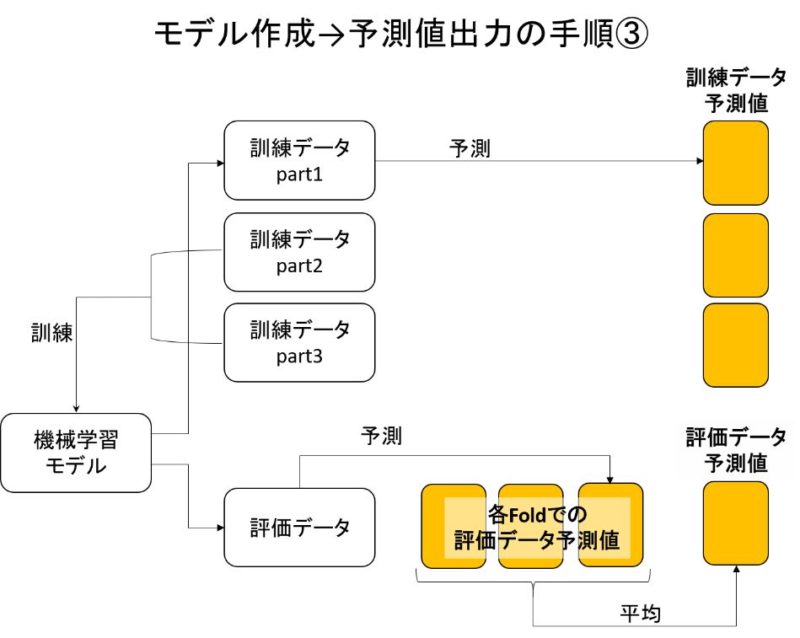
3回交差検証により、訓練データの予測値と評価データの予測値を出力できました。
ここで疑問が浮かぶ方もいるのではないでしょうか?
評価データの予測値を出力するのは分かるけど、
なんで訓練データの予測値まで出力するの??
なぜならスタッキングは、各モデルの訓練データ予測値を特徴量として次のモデルを作るからです。
イメージ画像は後程出します。
多様性のある複数モデルを作る
では次に、上記のような作業を様々なモデルで行いましょう。
オススメのモデル構成は次の通り。
- 3つのLightGBM(決定木の深さが深い・中・浅い)
- 2つのランダムフォレスト(決定木の深さが深い・浅い)
- 2つのニューラルネット(層が多い・少ない)
- 1つのSVM or 重回帰
つまり、多様性に富んだモデルを作るということですね。
この多様性が、相互補完を生み出して最終的な予測精度を上げてくれます。
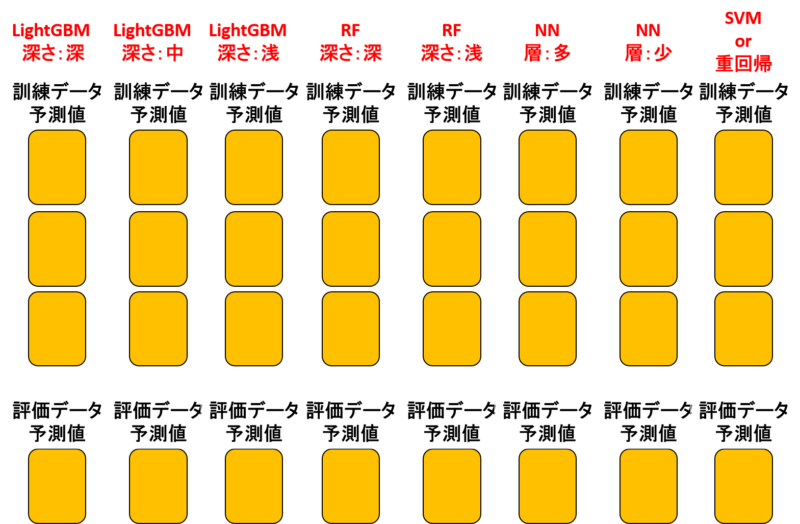
この作業が割と大変です。根気強くいきましょう。
私のようなモデルの種類以外に、例えば次のようなモデルも作れます。
- 使用する特徴量を限定する
- 特徴量のスケールを変える
- ハイパーパラメータを変える
このような変化を付けることも、「多様性を持ったモデル」の作成として成り立ちます。
訓練データ予測値で、新たなモデルを作る
次に、作成した訓練データ予測値を使用して次の機械学習モデルを作りましょう。
次のモデルは一般的に線形モデルであることが多いです。
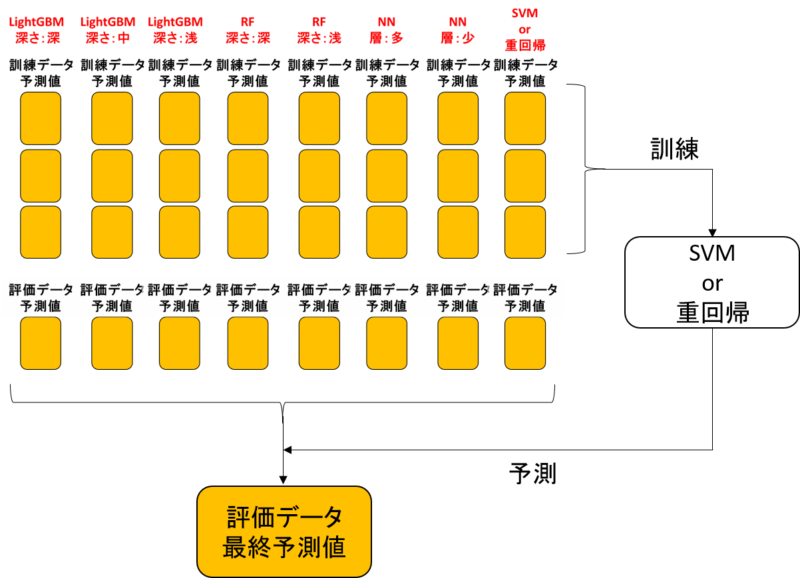
追記:最近はSVM・重回帰よりRassoのほうがいい気がしてます。モデルに寄るので要検討。
イメージとしては、SVMor重回帰は次のような要素を考慮して学習していると考えられます。
- 各モデルがどれほど正確か(偏回帰係数による調整)
また、スタッキングによって精度が上がるイメージは次の通り。
- 各モデルで生まれる誤差が平均されて正答値に近づく
- 各モデルが苦手とする予測値範囲を他のモデルが補完する
スタッキングに関する様々なアイデア
今回紹介した方法がスタッキングの絶対的な方法ではありません。
あくまで一例です。
スタッキングには様々なアイデアがあり、どれが最適かを判断する術はありません。
色々試してみて、「これがいいかもなぁ」と当たりを付けるほかないですね。
スタッキングのアイデアとしては次のようなものがあります。
- 2層ではなく3層にする
- 2層目に元の特徴量(予測値ではない)を残しておく
- 2層目の特徴量に目的の予測値以外を混ぜる(例えば「このデータは外れ値だ」のような予測)
- 各モデルの予測差を特徴量に加える
- 重要だが欠損が多い特徴量の予測値を2層目の特徴量として加える
はい。無限にありますね。
Kaggleのような「結果が全て」の世界では、このような検討が数多く行われています。
スタッキングのデメリット
スタッキングにもデメリットはもちろんあります。
計算コストの爆発
スタッキングは複数のモデルを作り、更に交差検証まで行うので計算コストが高くなります。
解決策としては、
- 計算コストが低いモデルを使う(XGboost→LightGBMに変えるなど)
- モデルの計算コストを減らす(決定木の数を最小限にするなど)
- スタッキングに使うモデルの数を減らす
- マシンパワーを強化する(クラウドサービスを利用する)
などです。
更なるブラックボックス化
まあ機械学習は元々ブラックボックスなんですが、スタッキングを使うと中身が全く分からなくなります。
Kaggleのような「結果が全て」ならOKなんですが、実務になると説明責任も出てきます。
AIエンジニアのつらいところですが、モデルが出来たら試運転をしてみましょう。
「どうやら精度がありそうだ」→「このモデルを使用しよう」という流れで信頼を勝ち取るしかないですね。
学習データに適合しすぎる
スタッキングは使用したデータに適合しすぎます。
スタッキングが裏目にでるケースは次の通り。
- モデル作成に使用したデータと、実際に予測したいデータの分布が違う
- データの数が少ない場合
1番目は特に時系列データにありがちですね。
例えば我々に与えられたデータは2018年のもので、予測したい隠されたデータが2019年版ならばスタッキングは2018年に適合しすぎます。
そのような場合は各モデルの予測値を単純に平均したものを最終的な予測値にするなど、少し適合を抑える処置が必要です。
まとめ
スタッキングについて理解は深まったでしょうか?
スタッキングは様々なハッカーが「コツ」を持っており、日々情報交換が行われています。
様々な情報を仕入れて、常に最新技術を取り入れましょう。
↓スタッキングも簡単に実装できます。
そして世界に革命を起こすこと間違いなしの機械学習全自動化ライブラリ「PyCaret」の使用方法や、今後の社会を予想した
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
も同時発売中です。
「PyCaret」を使いこなせば、22種類もの機械学習手法と一気に比較したり、ブラックボックスであるモデル内部の解析までわずか10数行のコードで行うことができます!
中身はこんな感じ↓
- Pythonのインストール
- Anaconda「JupyterNotebook」の起動
- 仮想環境構築
- データセット
- 中身の確認
- PyCaretを実装する
- ライブラリのインポート
- データ型を推測させる
- モデルの構築
- モデルの選択
- ハイパーパラメータチューニング
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- 機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
Python初心者でもインストール~全自動ライブラリ実装・解析まで出来るようになります。
980円:11080文字の教科書になっています。
全自動でもいいからパッと機械学習を実装したい!
「PyCaret」のような最新技術を使いこなしたいな。
という方には非常にオススメです。是非一読あれ!
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
↓こんな記事見てるド変態データサイエンティスト(誉め言葉)にピッタリのスクール↓

↓他にもおすすめのスクールあります↓
【参考書籍】テーブルデータでの機械学習技術について、現状日本一詳しい書籍です↓
【書評】↓

【参考】Kaggleでのスタッキングdiscussionリンク
【機械学習】LightGBMについて解説↓

コメント
ありがとうございます。
訓練データ予想値で新たなモデルを作る際、
訓練データ予想値を説明変数として用いるのは分かるのですが、目的変数として何を用いるのか文中では明確に示されていないような気がします。
記事全体として、訓練に使用する目的変数が示されていない例が多い気がするので、正確を期するなら明示すべきかと思います。
よろしくお願い致します。