
どうも、リンです。前回は探索的データ解析(EDA)のほんの一部を行っていきました。
↓前回記事

今回は、探索的データ解析(EDA)の続きです。
データを可視化することでデータセットに対する知見を深めましょう。
実際に探索的データ解析(EDA)をしていこう
取り敢えずPairPlot
探索的データ解析を(EDA)を進めていく定石は人によって様々ですが、私の場合は取り敢えずPairPlotをしてみます。
1 2 | sns.pairplot(concrete_data) plt.show() |
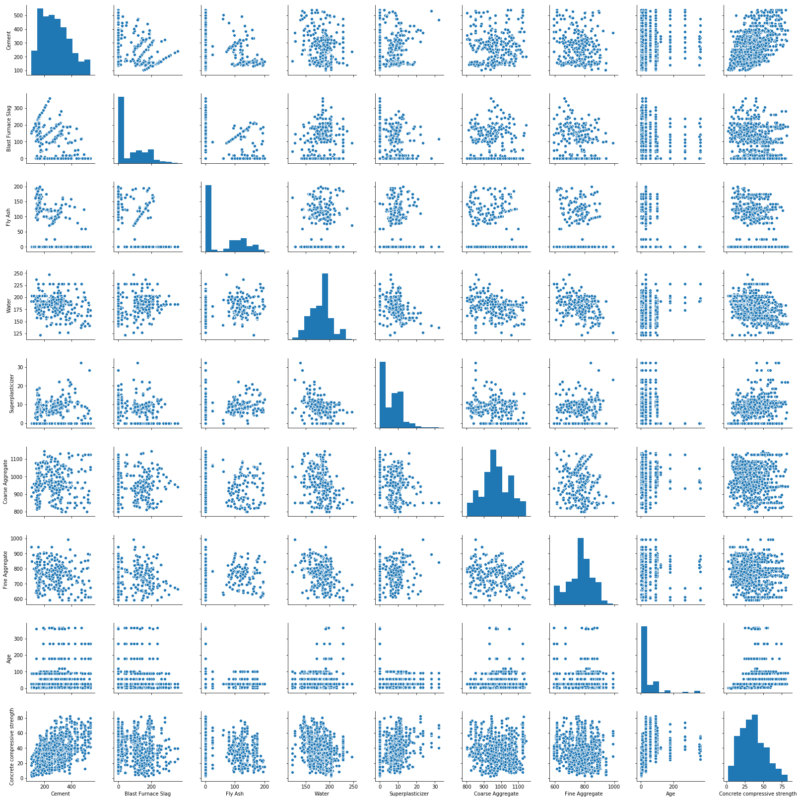
…何が起きているのか全くわかりませんね。少し解説します。
pythonのライブラリの一つ、matplotlibを基にした可視化ライブラリにseabornがあります。
pairplotとはseabornが提供する機能の一つです。
データセットの各変数同士の相関+各変数のヒストグラムを確認できます。
PairPlotから気になるデータを確認
表示したPairPlotから、気になるデータを確認していきましょう。
まずは目的変数であるコンクリート強度と説明変数のセメント量ですね。
1 | sns.pairplot(concrete_data, x_vars=['Cement'], y_vars=['Concrete compressive strength']) |
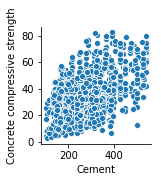
僅かな相関ではありますが、セメント量が増えるほどコンクリート強度は増すようですね。
コンクリートについて全く知識はありませんが、なんとなく納得ですね。
次に目的変数であるコンクリート強度と説明変数の高流動化剤量です
1 | sns.pairplot(concrete_data, x_vars=['Superplasticizer'], y_vars=['Concrete compressive strength']) |
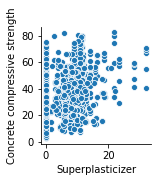
これも高流動化剤の量が増えるとコンクリート強度が増す?というかコンクリート強度の下限値が底上げされると言うほうが正確でしょうか。
脆いコンクリートになるのを避けたかったら高流動化剤を少しでも添加するのがいいかも知れません。
次は目的変数であるコンクリート強度と説明変数の材齢です。
1 | sns.pairplot(concrete_data, x_vars=['Age'], y_vars=['Concrete compressive strength']) |
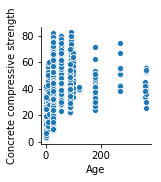
ふーむ。材齢が小さいとコンクリート強度は弱いようですし、材齢が大きくてもコンクリート強度は弱くなるようです。
材齢が小さい=コンクリートの硬化が進んでいない
材齢が大きい=コンクリートが劣化
ってことでしょうか?材齢も重要なポイントになってきそうですね…
1 | sns.distplot(concrete_data['Age'], kde=False, rug=False, bins=50) |
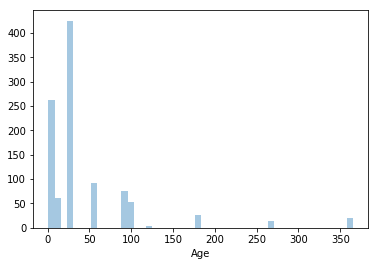
ちなみに材齢は0~100日くらいがほとんどらしいですね。あまり古い材料は使われていないようですね。
このように、PairPlotからはデータセットに関する重要な情報を引き出すことができます。
ここで得られる知見は、後の機械学習モデル改良で大きく役に立ちます。
闇雲のモデルを作るより、一度冷静にデータセットと向き合いましょう。
相関係数のヒートマップを確認
先ほどのPairPlotではプロットからぱっと見で相関を確認していました。
しかしデータサイエンスで「きっと~だと思う」は危険です。しっかり数値に落とし込まねば。
そこでseabornの機能で、相関係数のヒートマップを作りましょう。
1 2 3 | plt.figure(figsize=(10,10)) cmap = sns.color_palette("coolwarm", 200) sns.heatmap(concrete_data.corr(), square=True, annot=True, cmap=cmap) |
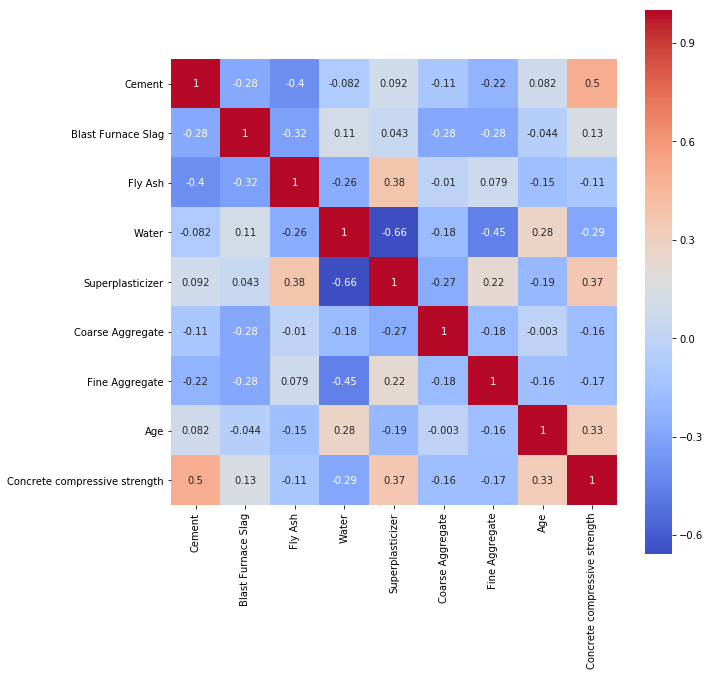
うーむ。非常にわかりやすい。
+1.0に近づくほど、正の相関に近い。-1.0に近づくほど負の相関に近いです。
ちょっと詳しく見てみましょうか。
SuperPlasticizer(高流動化剤)とWater(水)の相関は-0.66と、かなり負の相関があります。
1 | sns.pairplot(concrete_data, x_vars=['Superplasticizer'], y_vars=['Water']) |
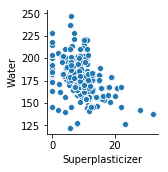
ほんまや…。高流動化剤と水を同時に増やすと何か不具合が生じるんでしょう。水っぽいコンクリートになっちゃうとか。
続いてCement(セメント)とFly Ash(フライアッシュ)を確認しましょう。相関は-0.40でした。
1 | sns.pairplot(concrete_data, x_vars=['Fly Ash'], y_vars=['Cement']) |
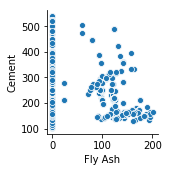
ちなみにフライアッシュとは、以下のようなモノのようです。
火力発電所で微粉炭を燃焼する際に副産されるもので、混和材やフライアッシュセメントとして用いる。JISでは、「JIS A 6201 コンクリート用フライアッシュ」および「JIS R 5213 フライアッシュセメント」として規定されている。良質なフライアッシュを使用すれば、単位水量の低減、ワーカビリティーの改善、水和発熱量の低下、長期強度および耐久性の増進、水密性の改善、化学抵抗性の改善、化学抵抗性の向上などの効果があり、ダムコンクリートなどのマスコンクリートに利用されてきた。フライアッシュの主成分はSiO2が50~70%程度、Al2O3が15~30%程度である。
https://www.weblio.jp/content/フライアッシュ
そしてなぜセメントとフライアッシュに負の相関があるかというと、以下のようフライアッシュはコンクリート材料の5~30%を混ぜ込むモノらしいです。
セメントとフライアッシュとを均一に混合してつくった混合セメントをいう。フライアッシュの分量は5%を超え30%以下である。ワーカビリティーが良く、発熱が少ない等の特長があるが、初期強度が低いなどの欠点もある。
https://www.weblio.jp/content/フライアッシュセメント
ふーむ。もちろん相関図を見ての通り、フライアッシュ0kgも沢山あるので、必ず必要っていうわけでは無さそうですね。
フライアッシュを増やせば、セメントの量は少なくする必要があるのでしょうか。
新しい説明変数として、材料全体に対するフライアッシュの比率とかを加えると機械学習モデルが向上するかもしれませんね。
新しい特徴量を作って確認する
このように、探索的データ解析を進めていくと「○○みたいな特徴量を作るとどうなるんだろう」と疑問に思います。
その場合は一度特徴量を作ってみて、可視化するとデータセットの意味をより深く理解できます。
例えば、先ほど書いた「材料全体に対するフライアッシュの比率」で特徴量を作ってみましょう。
1 2 3 4 5 6 7 | concrete_data['Density'] = concrete_data['Cement'] + concrete_data['Blast Furnace Slag'] \ + concrete_data['Fly Ash'] + concrete_data['Water'] + concrete_data['Superplasticizer'] \ + concrete_data['Coarse Aggregate'] + concrete_data['Fine Aggregate'] concrete_data['Fly Ash ratio'] = concrete_data['Fly Ash'] / concrete_data['Density'] sns.distplot(concrete_data['Fly Ash ratio'], kde=False, rug=False, bins=40) |
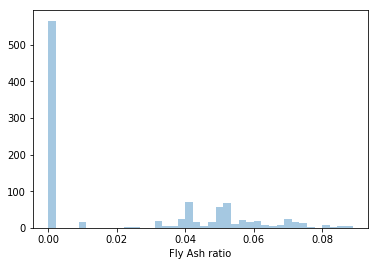
なるほど。フライアッシュは重量比0~10%程度で混合されていることがわかりますね。
これはモデル改良で重要な特徴量になっていきそうな気がします。
探索的データ解析(EDA)のコツは「思いついたら即実行」
さて、探索的データ解析(EDA)をほんの少しだけですがやっていきました。
探索的データ解析(EDA)を行う上で、大事な心構えがあります。
それは「思いついたら即実行」です。
探索的データ解析をしようと思うと、
これやって意味あるんかなぁ…
どうやってコード書けばいいのか分からないよ!
などなど、「やらないでおこう」と思いがちです。しかし、探索的データ解析は「探索的」と書いての通り、探索しないと始まらないんですよ。
「とりあえず冒険してみよう」が探索的データ解析ですからね。「思いついたら即実行」って意味が分かりますでしょうか?
コードの書き方とかも、私のブログでも紹介していくつもりですが、必死に調べればどこかで引っかかるハズですよ。
それでは今回の記事はここまで。次は基本的な機械学習の手法を用いて、モデルを作っていきましょう!
追記:機械学習完全マスター教科書販売中です(980円[期間限定]:24350文字の教科書です)
pythonの一般的な教本と一味違い、
- 第一に機械学習を最短経路で「実装」できる
- 第二に詳しい原理が理解できる
これらを重視して執筆しました。
普通の教本の1/4くらいの値段ですし、誰かに紹介すれば半額の紹介料が入るのですぐ元は取れます
★★★★★この価格でこのクオリティは凄すぎる
大学生ですが、これをつかって実験のレポートのデータ解析などにもつかえそうだと思いました! また、値段が安すぎて恐縮してます汗 凄すぎる…
レビュー欄より
★★★★★ 数ある教材の中でもトップクラスの分かりやすさ
これを機会に一度挫折したpythonを学び直そうと一念発起いたしました。いろいろなお勧めサイトの教材を拝見し購入しては失敗していましたが、ようやく超優良教材見つけました。知りたかった情報がすべて網羅されていて、この価格はなかなか無いと思います。今後の追加情報も期待したいです。
レビュー欄より
↑こんなコメントも頂きました!ありがとうございます(泣)
お役に立てて、必死に執筆した甲斐がありました(泣)(泣)
レビューはモチベに繋がるので、順次追記してコンテンツを増加していきます!乞うご期待!
追記[2020/03/14]:コンテンツ追加しました。
- ランダムフォレスト&LightGBM内部計算の可視化方法
- 内部可視化を基にした原理解説
- 学習の進行による予測分布の変化
- マテリアルズインフォマティクスへの活用方法
Python初心者であれば更に理解が深まり、玄人でも更なる原理や挙動の知見を得ることができるようになりました!
是非一読あれ~
↓リンク
機械学習はこれ一本!pythonインストール~機械学習実装まで完全理解講座
そして世界に革命を起こすこと間違いなしの機械学習全自動化ライブラリ「PyCaret」の使用方法や、今後の社会を予想した
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座
も同時発売中です。
「PyCaret」を使いこなせば、22種類もの機械学習手法と一気に比較したり、ブラックボックスであるモデル内部の解析までわずか10数行のコードで行うことができます!
中身はこんな感じ↓
- Pythonのインストール
- Anaconda「JupyterNotebook」の起動
- 仮想環境構築
- データセット
- 中身の確認
- PyCaretを実装する
- ライブラリのインポート
- データ型を推測させる
- モデルの構築
- モデルの選択
- ハイパーパラメータチューニング
- 学習結果の可視化
- Hyperparameters
- Residuals Plot
- Prediction Error Plot
- Cooks Distance Plot
- Recursive Feature Elimination
- Learnig Curve
- Validation Curve
- Manifold Learning
- Feature importance
- Stackingさせる
- 機械学習の未来について所感
- 機械学習は社会人必須ツールへと昇華(陳腐化)する
- 機械学習自動化で社会はこう変わる
- チームメンバーに求められるスキルも変化する
- データサイエンスとして突出した人材になるには?
- この記事を見たあなたは「先行者利益」を得る
Python初心者でもインストール~全自動ライブラリ実装・解析まで出来るようになります。
980円:11080文字の教科書になっています。
全自動でもいいからパッと機械学習を実装したい!
「PyCaret」のような最新技術を使いこなしたいな。
という方には非常にオススメです。是非一読あれ!
↓リンク
機械学習全自動化!?世界に革命を起こす「PyCaret」完全理解講座

次の記事↓

↓ 効率的なPython学習はオンラインスクールがオススメ ↓
コメント